
[Custom Thumbnail]
All the Code of the series can be found at the Github repository:
https://github.com/drifter1/compiler
Introduction
Hello it's a me again @drifter1! Today we continue with my Compiler Series, a series where we implement a complete compiler for a simple C-like language by using the C-tools Flex and Bison. In this article we will theoretically cover Register Allocation & Assignment. The actual implementation will start from next time on!Requirements:
Actually you need to read and understand all the topics that I covered in the series as a whole, as these articles will give you access to knowledge about:- What Compiler Design is (mainly the steps)
- For which exact Language the Compiler is build for (Tokens and Grammar)
- How to use Flex and Bison
- How to implement a lexer and parser for the language using those tools
- What the Symbol Table is and how we implement it
- How we combine Flex and Bison together
- How we can pass information from the Lexer to the Parser
- How we define operator priorities, precedencies and associativity
- What Semantic Analysis is (Attributes, SDT etc.)
- How we do the so called "Scope Resolution"
- How we declare types and check the type inter-compatibility for different cases that include function parameters and assignments
- How we check function calls later on using a "Revisit queue", as function declarations mostly happen after functions get used (in our Language)
- Intermediate Code Representations, including AST's
- How we implement an AST (structure and management)
- Action Rules for AST nodes and more
- The target system's architecture and its assembly language (MIPS)
- How we generate Assembly code for various cases
Difficulty:
Talking about the series in general this series can be rated:- Intermediate to Advanced
- Medium
Actual Tutorial Content
What is Register Allocation & Assignment
During compilation, the variables of a program have to be assigned to a small, specific range of registers. For example, in the case of our target architecture, which is MIPS, 32 general-purpose registers and 32 floating-point registers are available, meaning that we have to map the n-variables and various in-between results of a program to this limited number of registers. Because variables may not be used simultaneously for some time and the available registers are mostly less than the program's variables, registers can be assigned to multiple variables.Either way, two variables that are being used in the same instruction can't be assigned to the same exact register, cause that would corrupt the value. In the same way, we also don't want to move variables to different registers (the so called move insertion that puts variables in different registers during their lifetime) or even write them to memory (the so called spilling) that often, cause that would slow down our program.
So, what we want to accomplish can be summarized by:
- Limit the number of moves between registers, which makes variables "live" in different registers during their lifetime, instead of one
- Limit the action of storing variables into memory instead of registers (spilling)
Register Allocation vs. Assignment
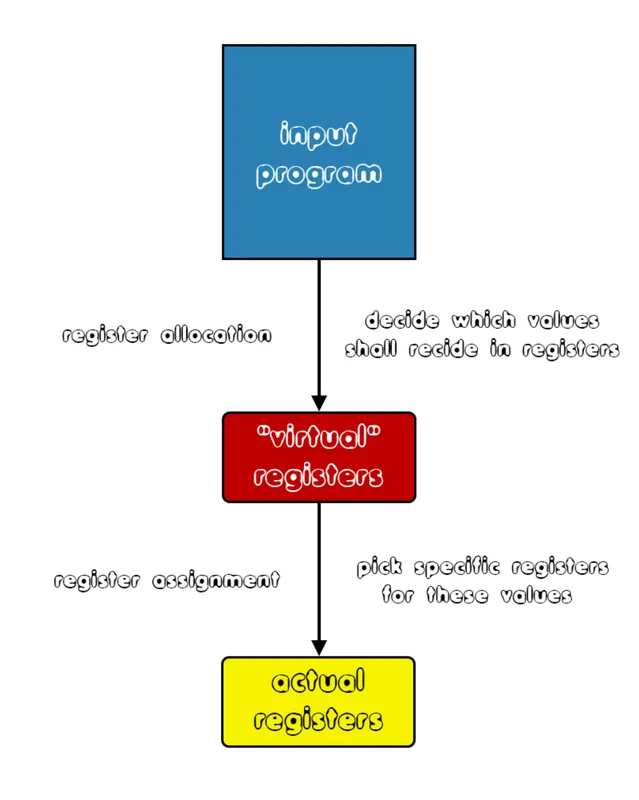
So, what's the difference between allocation and assignment, that we seem to use with the same meaning?- Register Allocation - decides which values of a program shall reside in registers
- Register Assignment - picks a specific register (or registers) for these values to reside in
[Custom diagram]
So, the first part of register allocation is simple, and we only have to decide which variables, instruction results and such, have to be stored in registers during the execution of the program. The second part is the most difficult one, as we will have to specify exact registers to which those "virtual" registers will be mapped to.
Register Assignment Approaches
Register assignment can been approached through various techniques, with each one having its own strengths and weaknesses.Local vs. Global Assignment
The first basic categorization has to do with how we want to assign those registers:- Local assignment - assign registers separately for each basic block
- Global assignment - assign registers throughout the whole program, giving priority to highly used variables in inner loops and mostly identifying live ranges and split ranges for the variables
Assign by Usage Count
To assign registers globally, or even locally in some cases, we can use a heuristic method/algorithm that assigns registers to variables that are use the most and so depending on their usage count.Tweaked Example from Ref3
We have an architecture with 3 available registers.A loop of some program contains the following variables:
- X - 5 references
- Z - 5 references
- Y - 4 references
- D - 3 references
- E - 1 reference
Assign by Graph Coloring
The most predominant approach that we will also use to solve the allocation-assignment problem in our own compiler is Graph-coloring! Graph-coloring was proposed by Chaitin, and that's why we also call the algorithm: Chaitin-style graph-coloring. In this approach we represent the live ranges of variables, temporaries etc. as nodes in a so called Interference graph. Live ranges that interfere (are simultaneously at at least one program point) are connected through edges. That way, register allocation is reduced to a graph coloring problem, in which colors (registers) are assigned to the nodes. Two nodes that are connected by an edge don't receive the same color (register).The information of lifetime is basically already stored in some way or another inside of the symbol table!
Procedure
The main steps of Graph-coloring register allocation are: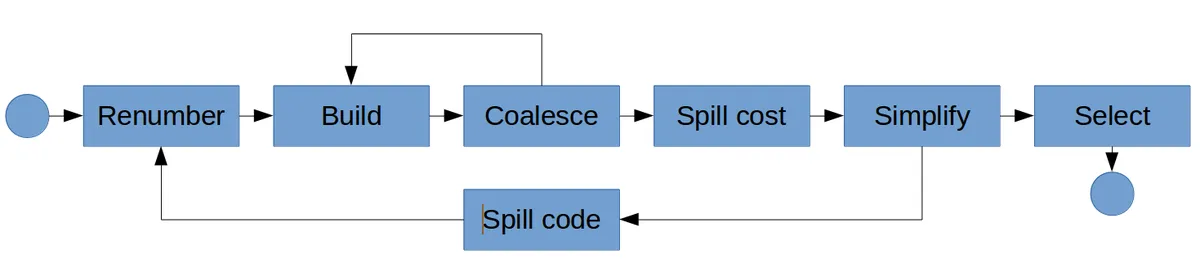
[Image 1]
where we:
- Discover variable live-ranges (Renumber)
- Build interference graph
- Merge live-ranges of non-interfering variables (Coalesce)
- Compute the spill cost of each variable
- Order the nodes in the interference graph (Simplify)
- Insert spill code-instructions (loads and stores between registers and memory)
- Assign a register to each variable (Select)
Drawbacks
There are of course some major drawbacks in this graph-coloring approach:- Graph-coloring is an NP-complete problem, and so finding the minimal coloring graph (register allocation) is of high computational complexity. In the worst case, its quadratic to the number of live-ranges
- When not using live-range splitting variables are spilled everywhere, inserting store instructions as early as possible and load instructions as late as possible.
- A variable that is not spilled keeps the same register throughout its whole lifetime
- The traditional formulation assumes that all registers are non-overlapping and for general-purposes. It can't handle irregular architectural features like overlapping register pairs, special purpose registers and multiple register banks
Optimizations
An improvement for Chaitin's method has been found by Briggs. This method is called conservative coalescing. It adds a criteria to decide when two live ranges can be merged. Thus, in addition to the non-interfering requirement, two variables can only be coalesced if their merging doesn't cause further spilling. Briggs, also introduced another improvement which is biased coloring and tries to assign the same color to live ranges that are copy related.Example
The simplify-select process is shown below: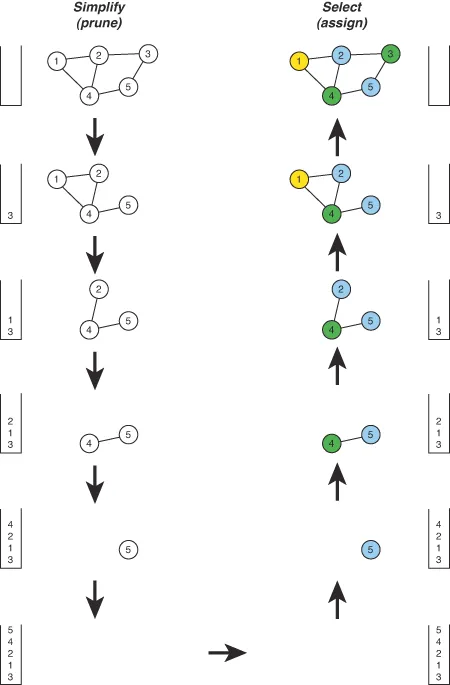
[Image 2]
As you can see:
- Select - is the phase that selects a color (register) for each node, repeatedly popping a node of the stack, re-inserting it to the graph and assigning a color that is different from all of its neighbours.
- Simplify - is the phase that chooses the order of assignments, inserting the nodes into the stack and making the node a spill candidate when more than k (number of available colors-registers) neighbors are removed. Here we basically examine how the various nodes interfere.
Linear Scan
Linear scan is a method, where variables are linearly scanned to determine their live range that is represented as an interval. Once the live ranges of all variables have been figured out, the intervals are traversed chronologically. The major drawback of this method is its greedy aspect that makes spilled variables stay spilled for their lifetime. The method is imprecise due to the use of live intervals rather than live ranges. This algorithm is quite efficient, cause after computing live intervals the algorithm runs in linear time, producing good code and allocating in steps of one pass, being able to generate code during iteration. Either way, other techniques like Graph-coloring are superior in many cases.RESOURCES
References:
- https://www.techopedia.com/definition/21664/register-allocation
- https://www.geeksforgeeks.org/computer-organization-register-allocation/
- https://web.cs.wpi.edu/~cs544/PLT11.6.1.html [11.6.1 - 11.6.5]
- https://web.stanford.edu/class/archive/cs/cs143/cs143.1128/lectures/17/Slides17.pdf
- http://www.lighterra.com/papers/graphcoloring/
- https://en.wikipedia.org/wiki/Register_allocation
Images:

- http://www.lighterra.com/papers/graphcoloring/
Previous parts of the series
General Knowledge and Lexical Analysis
- Introduction
- A simple C Language
- Lexical Analysis using Flex
- Symbol Table (basic structure)
- Using Symbol Table in the Lexer
Syntax Analysis
- Syntax Analysis Theory
- Bison basics
- Creating a grammar for our Language
- Combine Flex and Bison
- Passing information from Lexer to Parser
- Finishing Off The Grammar/Parser (part 1)
- Finishing Off The Grammar/Parser (part 2)
Semantic Analysis (1)
- Semantic Analysis Theory
- Semantics Examples
- Scope Resolution using the Symbol Table
- Type Declaration and Checking
- Function Semantics (part 1)
- Function Semantics (part 2)
Intermediate Code Generation (AST)
- Abstract Syntax Tree Principle
- Abstract Syntax Tree Structure
- Abstract Syntax Tree Management
- Action Rules for Declarations and Initializations
- Action Rules for Expressions
- Action Rules for Assignments and Simple Statements
- Action Rules for If-Else Statements
- Action Rules for Loop Statements and some Fixes
- Action Rules for Function Declarations (part 1)
- Action Rules for Function Declarations (part 2)
- Action Rules for Function Calls
Semantic Analysis (2)
- Datatype attribute for Expressions
- Type Checking for Assignments
- Revisit Queue and Parameter Checking (part 1)
- Revisit Queue and Parameter Checking (part 2)
- Revisit Queue and Parameter Checking (part 3)
- Revisit Queue and Parameter Checking (part 4)
- Revisit Queue and Assignment Checking (part 1)
- Revisit Queue and Assignment Checking (part 2)
- Revisit Queue and Assignment Checking (part 3)
Machine Code Generation
- Machine Code Generation Principles
- MIPS Instruction Set
- Simple Examples in MIPS Assembly
- full_example.c in MIPS Assembly (part 1)
- full_example.c in MIPS Assembly (part 2)
- Generating Code for Declarations and Initializations
- Generating Code for Array Initializations and String Messages
Final words | Next up on the project
And this is actually it for today's post! I hope that I explained everything as much as I needed to. Next time we will get into the implementation of today's knowledge.Next up on this series, in general, are:
- Machine Code generation (MIPS Assembly)
- Various Optimizations in the Compiler's Code
Which are all topics for which we will need more than one article to complete them. Also, note that we might also get into AST Code Optimizations later on, or that we could even extend the Language by adding complex datatypes (structs and unions), more rules etc.
So, see ya next time!
GitHub Account:
https://github.com/drifter1
Keep on drifting! ;)