
[Custom Thumbnail]
All the Code of the series can be found at the Github repository:
https://github.com/drifter1/compiler
Introduction
Hello it's a me again @drifter1! Today we continue with my Compiler Series, a series where we implement a complete compiler for a simple C-like language by using the C-tools Flex and Bison. In this article we will start with the implementation of Register Allocation, that will be covered in multiple parts...Requirements:
Actually you need to read and understand all the topics that I covered in the series as a whole, as these articles will give you access to knowledge about:- What Compiler Design is (mainly the steps)
- For which exact Language the Compiler is build for (Tokens and Grammar)
- How to use Flex and Bison
- How to implement a lexer and parser for the language using those tools
- What the Symbol Table is and how we implement it
- How we combine Flex and Bison together
- How we can pass information from the Lexer to the Parser
- How we define operator priorities, precedencies and associativity
- What Semantic Analysis is (Attributes, SDT etc.)
- How we do the so called "Scope Resolution"
- How we declare types and check the type inter-compatibility for different cases that include function parameters and assignments
- How we check function calls later on using a "Revisit queue", as function declarations mostly happen after functions get used (in our Language)
- Intermediate Code Representations, including AST's
- How we implement an AST (structure and management)
- Action Rules for AST nodes and more
- The target system's architecture and its assembly language (MIPS)
- How we generate Assembly code for various cases
Difficulty:
Talking about the series in general this series can be rated:- Intermediate to Advanced
- Medium
Actual Tutorial Content
Fixing past mistakes
Let's head back to the AST Structures that we used for the Intermediate Code Representation. While traversing through the tree that gets generated by the end of the Intermediate Code Generation procedure there was a small bug that needed fixing, but we never really got into it.AST structures fix
Using our custom function ast_traversal() that uses ast_print_node() to print out node information we basically loop through all the nodes of the AST in post-fix fashion mostly. But, inside of the left-and-right child cases, which are the ARITHM_NODE, BOOL_NODE, REL_NODE and EQU_NODE types of AST Nodes, we had to comment out the left and right traversal, because of a segmentation fault!So, after quite a few changes I finally found out what the problem was, and it was really really stupid. The basic AST_Node structure is defined as following:
typedef struct AST_Node{
enum Node_Type type; // node type
struct AST_Node *left; // left child
struct AST_Node *right; // right child
}AST_Node;Either way, as an example, the Arithmetic Node now has to be declared like this:
typedef struct AST_Node_Arithm{
enum Node_Type type; // node type
struct AST_Node *left; // left child
struct AST_Node *right; // right child
// data type of result
int data_type;
// operator
enum Arithm_op op;
}AST_Node_Arithm;Un-commenting left and right traversal
So, after this fix, the ast_traversal() function's case for those nodes now becomes:...
/* left and right child cases */
if(node->type == BASIC_NODE || node->type == ARITHM_NODE ||
node->type == BOOL_NODE || node->type == REL_NODE ||
node->type == EQU_NODE){
ast_traversal(node->left);
ast_traversal(node->right);
ast_print_node(node); // postfix
}
...New structures
Thinking about the problem of register allocation, we first have to find which exact values and variables need to be stored inside of registers. To simplify the problem, we will make a global assignment for the variables and temporary variables of the main function. So, variables or temporary variables (that you will understand later on) have to be assigned to some registers (or vise versa).Variable Array
We already have the information of the "actually declared" variables stored inside of the Symbol Table, but temporary variables have not been covered!So, in order to be able to apply more functions later on, we will store the symbol table's variables and other temporary variables that are needed inside of the code into a new structure that stores the names of those variables. This structure is also followed by the variable count: "var_count" and the temporary variable count: "temp_count".
That way, we only need to create an dynamic string array var_name to which we will insert variables using a new function called insertVar() and get the variable index of each variable that will also correspond to the graph_index or ID later on using another new function called getVarIndex(). To print out the information of this array more easily for debugging purposes, we will also define a function called printVarArray().
As a diagram this looks like this:
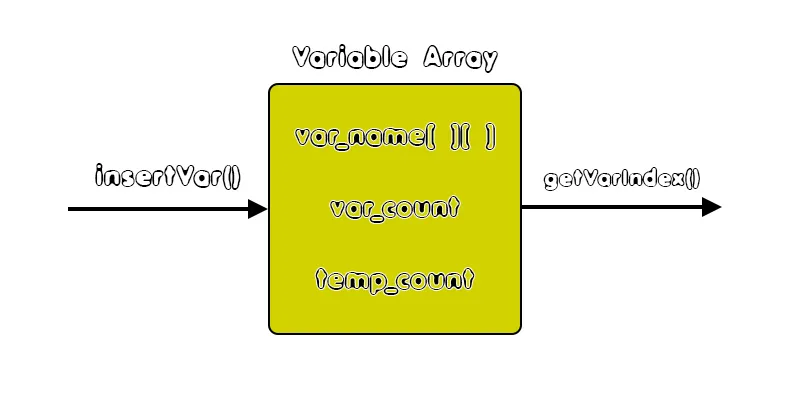
In our header file we basically only have to define the following:
/* Variable Array */
static char **var_name;
static int var_count = 0;
static int temp_count = 0;
/* Variable Array Functions */
void insertVar(char *name);
int getVarIndex(char *name);
void printVarArray();The actual implementation of these functions, will be covered in the next part!
Adjacency Graph
Having all the variables (temporary or not) stored inside of this array, we can now also create a graph with adjacency list implementation that will tell us which variables can't have the same register-color. The index of each variable inside of the Variable Array is equal to the graph index-list that this variable resides in.As a structure we basically only need to define an array of adjacency lists and a counter of the vertices that have been inserted (vertexCount). The adjacency list only contains the index of the variable inside of "var_name" and a pointer to the next item of the list. In other words we have:
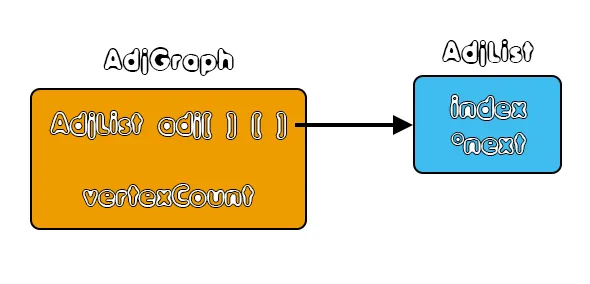
In C-code this becomes:
/* Adjacency List */
typedef struct AdjList{
int index;
struct AdjList *next;
}AdjList;
/* Adjacency Graph */
typedef struct AdjGraph{
AdjList **adj;
int vertexCount;
}AdjGraph;To manage this structure we basically only have to define:
- a static graph structure that is globally accessible (g)
- an initialization function (initGraph)
- an insertion function (insertEdge)
- a print function (printGraph)
When we get into the actual register assignment procedure, we will also have to define a graph coloring function, into which we will get in another part...
Tweaking previous structures
Seeing that the new register assignment/allocation structures that we defined, we can already see that previous structures will need tweaking. More specifically, we have to tweak the AST Structures (again) and the Symbol Table structure. To be able to loop through the AST Nodes that have been generated through parsing, we will also have to store those trees inside of global variables...Symbol Table
The symbol table structure "list_t" has to be extended by two more entries, which are:- g_index - the variable array (var_name) or graph index
- reg_name - the assigned register name-value
As a diagram we have:
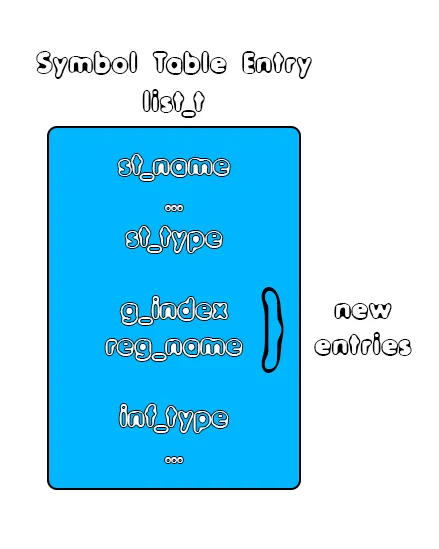
AST Nodes
To manage temporary variables, we will have to store the g_index of those variables inside of the corresponding AST Node structure they belong into. Those are basically the Arithm, Bool, Rel and Equ nodes that we also tweaked earlier and the Func_call, which's return value has to be stored inside of some register.As diagrams we have:
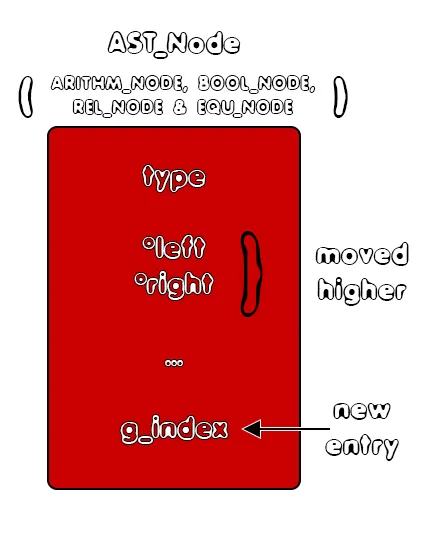
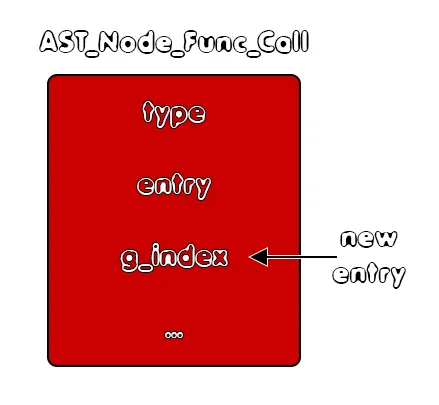
To get the g_index from such a structure we will define a new function called getGraphIndex(), which will also be covered in another part...
AST Trees
A program in our language is: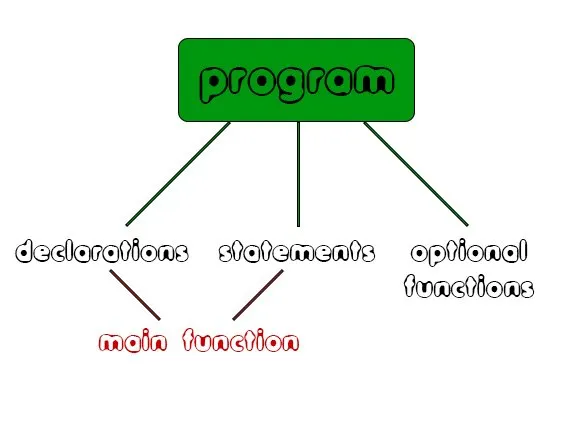
Those 3 AST nodes reside inside of the program-rule and can be easily stored inside of newly defined variables.
Let's define those variables inside of ast.h as:
static AST_Node* main_decl_tree; /* main function's declarations AST Tree */
static AST_Node* main_func_tree; /* main function's statements AST Tree */
static AST_Node* opt_func_tree; /* optional functions AST Tree */To set the value of those 3 variables, we basically only have to write the following code into the program-rule of parser.y:
program:
declarations { main_decl_tree = $1; ast_traversal($1); }
statements { main_func_tree = $3; ast_traversal($3); }
RETURN SEMI functions_optional { opt_func_tree = $7; ast_traversal($7); }
;A quite early version of the final code that we will end-up with, can already be found on the GitHub repository! Either way, I would suggest you to wait until the other parts, cause things might get a little bit confusing...
RESOURCES
References:
No references, just using code that I implemented in my previous articles.Images:
All of the images are custom-made!Previous parts of the series
General Knowledge and Lexical Analysis
- Introduction
- A simple C Language
- Lexical Analysis using Flex
- Symbol Table (basic structure)
- Using Symbol Table in the Lexer
Syntax Analysis
- Syntax Analysis Theory
- Bison basics
- Creating a grammar for our Language
- Combine Flex and Bison
- Passing information from Lexer to Parser
- Finishing Off The Grammar/Parser (part 1)
- Finishing Off The Grammar/Parser (part 2)
Semantic Analysis (1)
- Semantic Analysis Theory
- Semantics Examples
- Scope Resolution using the Symbol Table
- Type Declaration and Checking
- Function Semantics (part 1)
- Function Semantics (part 2)
Intermediate Code Generation (AST)
- Abstract Syntax Tree Principle
- Abstract Syntax Tree Structure
- Abstract Syntax Tree Management
- Action Rules for Declarations and Initializations
- Action Rules for Expressions
- Action Rules for Assignments and Simple Statements
- Action Rules for If-Else Statements
- Action Rules for Loop Statements and some Fixes
- Action Rules for Function Declarations (part 1)
- Action Rules for Function Declarations (part 2)
- Action Rules for Function Calls
Semantic Analysis (2)
- Datatype attribute for Expressions
- Type Checking for Assignments
- Revisit Queue and Parameter Checking (part 1)
- Revisit Queue and Parameter Checking (part 2)
- Revisit Queue and Parameter Checking (part 3)
- Revisit Queue and Parameter Checking (part 4)
- Revisit Queue and Assignment Checking (part 1)
- Revisit Queue and Assignment Checking (part 2)
- Revisit Queue and Assignment Checking (part 3)
Machine Code Generation
- Machine Code Generation Principles
- MIPS Instruction Set
- Simple Examples in MIPS Assembly
- full_example.c in MIPS Assembly (part 1)
- full_example.c in MIPS Assembly (part 2)
- Generating Code for Declarations and Initializations
- Generating Code for Array Initializations and String Messages
- Register Allocation & Assignment Theory
Final words | Next up on the project
And this is actually it for today's post! I hope that I explained everything as much as I needed to. Next time we will continue with part 2.Next up on this series, in general, are:
- Machine Code generation (MIPS Assembly)
- Various Optimizations in the Compiler's Code
Which are all topics for which we will need more than one article to complete them. Also, note that we might also get into AST Code Optimizations later on, or that we could even extend the Language by adding complex datatypes (structs and unions), more rules etc.
So, see ya next time!
GitHub Account:
https://github.com/drifter1
Keep on drifting! ;)