
[Custom Thumbnail]
All the Code of the series can be found at the Github repository:
https://github.com/drifter1/compiler
Introduction
Hello it's a me again @drifter1! Today we continue with my Compiler Series, a series where we implement a complete compiler for a simple C-like language by using the C-tools Flex and Bison. In this article we will generate Assembly Code for the case of Array Initializations (tweaking the code of the previous article) and also get into how we declare the String Messages, that get printed out using our custom print() function.Requirements:
Actually you need to read and understand all the topics that I covered in the series as a whole, as these articles will give you access to knowledge about:- What Compiler Design is (mainly the steps)
- For which exact Language the Compiler is build for (Tokens and Grammar)
- How to use Flex and Bison
- How to implement a lexer and parser for the language using those tools
- What the Symbol Table is and how we implement it
- How we combine Flex and Bison together
- How we can pass information from the Lexer to the Parser
- How we define operator priorities, precedencies and associativity
- What Semantic Analysis is (Attributes, SDT etc.)
- How we do the so called "Scope Resolution"
- How we declare types and check the type inter-compatibility for different cases that include function parameters and assignments
- How we check function calls later on using a "Revisit queue", as function declarations mostly happen after functions get used (in our Language)
- Intermediate Code Representations, including AST's
- How we implement an AST (structure and management)
- Action Rules for AST nodes and more
- The target system's architecture and its assembly language (MIPS)
- How we generate Assembly code for various cases
Difficulty:
Talking about the series in general this series can be rated:- Intermediate to Advanced
- Medium
Actual Tutorial Content
Array Initializations
Various Fixes and Tweaks
Before we get into Array Initializations, we should first make sure that everything is working properly.variable rule
First of all, we have to be able to check if an array has been initialized or not. This can be done quite easily by setting the dynamic array "vals"of the symbol table item that corresponds to this array to NULL, when this array is not being filled with values from the beginning. So, inside of the "variable"-rule we have to write:variable:
...
| ID array
{
if(declare == 1){
$1->st_type = ARRAY_TYPE;
$1->array_size = $2;
$1->vals = NULL;
$$ = $1;
}
}
;array_init rule
Making an example file that initializes arrays, we can also find out that the error message: "Array init at lineno doesn't contain the right amount of values!" gets triggered. This tells us that we don't check the value of the correct sub-rule! More specifically, we took the value of the ID, even though that value gets set later on. So, to fix this, we simply have to check if the value of the "array" sub-rule, that contains the array_size of the currently declared array is equal to the number of elements in the "vals" array, which is "vc". Additionally, we should also set the "st_type" to ARRAY_TYPE, cause else the array is being treated like a variable.The code of the new "array_init"-rule is:
array_init: ID array ASSIGN LBRACE values RBRACE
{
// $2 contains array_size
if($2 != vc){
fprintf(stderr, "Array init at %d doesn't contain the right amount of values!\n", lineno);
exit(1);
}
$1->st_type = ARRAY_TYPE;
$1->vals = vals;
$1->array_size = $2;
$$ = $1;
vc = 0;
}
;generate_data_declarations() tweaks
Declaring an array in MIPS Assembly, we can also initialize this array directly from .data. To do that, we simply write:name: .datatype {values}So, supposing that the "res" double array of full_example.c gets the values: 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, meaning that res[6] = {0.5, 1.5, 2.5, 3.5, 4.5, 5.5}, we can write the following Assembly code:
res: .double 0.500000, 1.500000, 2.500000, 3.500000, 4.500000, 5.500000Thus, we will use the previously declared ".space" declaration, when an array is not initialized, while using this "new" form, when the entries of the array have been initialized (vals != NULL).
Inside of the code generation function, we simply have to make separate cases for the "initialized" and "not initialized". To print out the values, in the case of array inits, we simply have to loop through the "vals" array, putting ", " after each value.
Here, a diagram that explains what we will be doing:

The datatypes and their sizes are:

The final code is:
else if (l->st_type == ARRAY_TYPE){
/* not initialized */
if(l->vals == NULL){
if (l->inf_type == INT_TYPE){
fprintf(fp, "%s: .space %d\n", l->st_name, l->array_size*4);
}
else if (l->inf_type == REAL_TYPE){
fprintf(fp, "%s: .space %d\n", l->st_name, l->array_size*8);
}
else if (l->inf_type == CHAR_TYPE){
fprintf(fp, "%s: .space %d\n", l->st_name, l->array_size*1);
}
}
/* initialized */
else{
if (l->inf_type == INT_TYPE){
fprintf(fp, "%s: .word ", l->st_name);
for(j = 0; j < l->array_size - 1; j++){
fprintf(fp, "%d, ", l->vals[j].ival);
}
fprintf(fp, "%d\n", l->vals[l->array_size - 1].ival);
}
else if (l->inf_type == REAL_TYPE){
fprintf(fp, "%s: .double ", l->st_name);
for(j = 0; j < l->array_size - 1; j++){
fprintf(fp, "%f, ", l->vals[j].fval);
}
fprintf(fp, "%f\n", l->vals[l->array_size - 1].fval);
}
else if (l->inf_type == CHAR_TYPE){
fprintf(fp, "%s: .byte ", l->st_name);
for(j = 0; j < l->array_size - 1; j++){
fprintf(fp, "%c, ", l->vals[j].cval);
}
fprintf(fp, "%c\n", l->vals[l->array_size - 1].cval);
}
}
}String Messages
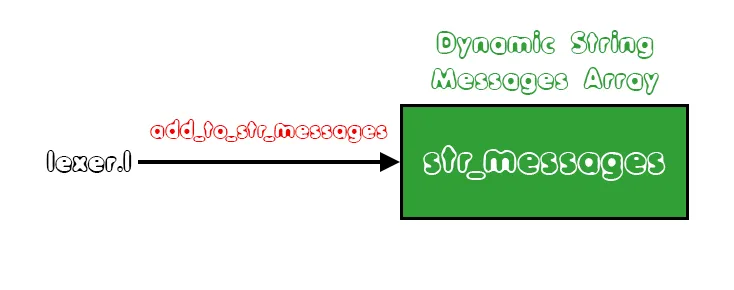
We don't store the string messages in any point except the AST Node that corresponds to calling parameters of function, supposing a STRING also occurs in the custom print() function. This now has to be changed!Dynamic String Message Array
The strings that occur through-out the file parsing process will be stored in a new array called "str_messages". This array needs a counter variable "num_of_msg" that will store the number of elements (strings) that have been stored inside of this new array. To add an element to this dynamic array, we will define a new function called "add_to_str_messages(), that we will cover later on.So, to summarize, we make the following changes to the symbol table files:
symtab.h:
...
static char **str_messages;
...
// String Messages
void add_to_str_messages(char *str);
--------------------------
symtab.c:
...
/* number of messages */
int num_of_msg = 0;
...
/* String Messages */
void add_to_str_messages(char *str){
...
}add_to_str_messages() function
This function is quite simple to write, we just need a separate case for the first insertion, as the array has to be allocated for the first time using "malloc". Afterwards, we will reallocate that space using "realloc". To insert the new string, we have to allocate enough space for that entry in the corresponding entry of that array using "malloc" again. To copy the new string to that newly allocated space, we have to use "strcpy". Lastly, we also have to increase the counter "num_of_msg".The final code is:
void add_to_str_messages(char *str){
/* manage space for strings */
if(num_of_msg == 0){
str_messages = (char**) malloc(1*sizeof(char*));
}
else{
str_messages = (char**) realloc(str_messages, (num_of_msg + 1)*sizeof(char*));
}
/* allocate space for the string */
str_messages[num_of_msg] = (char*) malloc((strlen(str) + 1) * sizeof(char));
/* copy string */
strcpy(str_messages[num_of_msg], str);
/* increase counter */
num_of_msg++;
}lexer.l
This function will be called inside of the lexer, in the {STRING}-rule, and of course before the string gets returned to the parser!As a diagram we have:
We simply change the code to:
{STRING} {
add_to_str_messages(yytext);
yylval.val.sval = malloc(yyleng * sizeof(char));
strcpy(yylval.val.sval, yytext); return STRING;
}generate_data_declarations() changes
To generate the code for those strings, which is of the format: "name: .asciiz msg", we of course have to change the generation function of ".data". We basically, just have to loop through the dynamic array "str_messages", printing out the string messages in that format.So, the code looks like this:
for(i = 0; i < num_of_msg; i++){
fprintf(fp, "msg%d: .asciiz %s\n", (i + 1), str_messages[i]);
}Running for tweaked version of full_example.c
Consider the full_example.c file tweaked to initialize the res array with the values that we spoke of before. Running our compiler for that example we will basically get this new "initialized array" declaration, and also message declarations.The "out.s" looks like this:
.data
c: .byte 'c'
i: .word 0
p: .word 0
val: .double 2.500000
res: .double 0.500000, 1.500000, 2.500000, 3.500000, 4.500000, 5.500000
msg1: .asciiz "\n"
msg2: .asciiz "\n"
msg3: .asciiz "iteration: 3\n"
msg4: .asciiz " "
msg5: .asciiz "\n"Note, that the code is not optimized, creating the same message ("\n") for each occurrence in the file! Either way, we get all of them, and can work with them much easier, as they are labeled incrementally. The print() function will just have to use msgX as the parameter, when a string gets printed out!
RESOURCES
References:
No references, just using code that I implemented in my previous articles.Images:
All of the images are custom-made!Previous parts of the series
General Knowledge and Lexical Analysis
- Introduction
- A simple C Language
- Lexical Analysis using Flex
- Symbol Table (basic structure)
- Using Symbol Table in the Lexer
Syntax Analysis
- Syntax Analysis Theory
- Bison basics
- Creating a grammar for our Language
- Combine Flex and Bison
- Passing information from Lexer to Parser
- Finishing Off The Grammar/Parser (part 1)
- Finishing Off The Grammar/Parser (part 2)
Semantic Analysis (1)
- Semantic Analysis Theory
- Semantics Examples
- Scope Resolution using the Symbol Table
- Type Declaration and Checking
- Function Semantics (part 1)
- Function Semantics (part 2)
Intermediate Code Generation (AST)
- Abstract Syntax Tree Principle
- Abstract Syntax Tree Structure
- Abstract Syntax Tree Management
- Action Rules for Declarations and Initializations
- Action Rules for Expressions
- Action Rules for Assignments and Simple Statements
- Action Rules for If-Else Statements
- Action Rules for Loop Statements and some Fixes
- Action Rules for Function Declarations (part 1)
- Action Rules for Function Declarations (part 2)
- Action Rules for Function Calls
Semantic Analysis (2)
- Datatype attribute for Expressions
- Type Checking for Assignments
- Revisit Queue and Parameter Checking (part 1)
- Revisit Queue and Parameter Checking (part 2)
- Revisit Queue and Parameter Checking (part 3)
- Revisit Queue and Parameter Checking (part 4)
- Revisit Queue and Assignment Checking (part 1)
- Revisit Queue and Assignment Checking (part 2)
- Revisit Queue and Assignment Checking (part 3)
Machine Code Generation
- Machine Code Generation Principles
- MIPS Instruction Set
- Simple Examples in MIPS Assembly
- full_example.c in MIPS Assembly (part 1)
- full_example.c in MIPS Assembly (part 2)
- Generating Code for Declarations and Initializations
Final words | Next up on the project
And this is actually it for today's post! I hope that I explained everything as much as I needed to. Next time we will continue with more stuff around Machine Code generation!Next up on this series, in general, are:
- Machine Code generation (MIPS Assembly)
- Various Optimizations in the Compiler's Code
Which are all topics for which we will need more than one article to complete them. Also, note that we might also get into AST Code Optimizations later on, or that we could even extend the Language by adding complex datatypes (structs and unions), more rules etc.
So, see ya next time!
GitHub Account:
https://github.com/drifter1
Keep on drifting! ;)