Gráficas de dispersión
Tendencia y CorrelaciónCuando revisamos las cifras de contagios por COVID-19 podemos inferir que han disminuido en los países que tienen más del 80% de su población objetivo vacunada, y en los que no cuentan con vacunas a nivel nacional las cifras podrían seguir oscilando hasta con tendencia alcista. Se puede dar el caso que tengamos unas gráficas con pendiente negativa (a la baja) y que se pueda dar una correlación lineal entre el número de contagiados y el porcentaje de personas vacunadas, el primer caso mencionado antes, pero cuando existe una dispersión amplia de datos es poco probable que se pueda interpretar como una tendencia hacia arriba o hacia abajo y mucho menos proponer una correlación entre los parámetros señalados.
Este será mi tema a analizar en este artículo, Modelos y ajuste de datos experimentales, que busca analizar la tendencia de un variable dependiente de un parámetro que se considera de referencia.

En algunas ocasiones es muy común escuchar "no tienen ninguna relación", como por ejemplo cuando se hace la gráfica de la altura de 30 niños del salón de clases y la longitud promedio del cabello de cada uno de ellos. Una niña puede medir 1,20 metros de estatura y su cabello extremadamente largo de unos 50 centímetros de largo, mientras que otra chica de esa misma altura puede tener un cabello corto de unos 27 cm y tal vez un niño de esa altura puede tener su cabello al ras de su cabeza con 3 milímetros y su compañero lo tendría de unos 5 cm de largo, en fin no está definida una tendencia de los datos experimentales, que nos pueda encaminar a proponer una conclusión entre estos 2 parámetros, no existiendo una correlación entre ellos.

Correlación:La dispersión de los puntos experimentales, la data de estatura de los niños y la longitud del cabello, es muy notable, es decir están separados uno del otro, por lo que para una misma estatura podemos tener hasta 6 valores diferentes de la variable "largo del cabello", no existiendo proporcionalidad entre los 2 parámetros.

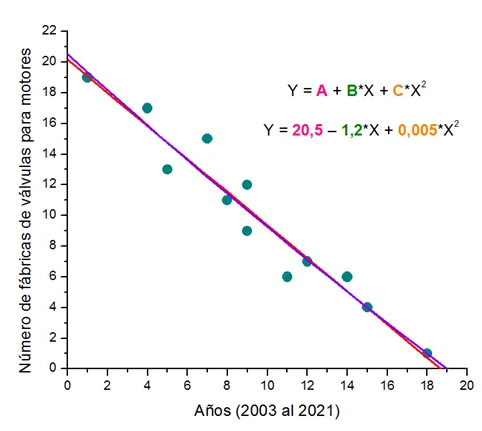
A manera de ejemplo, podemos realizar un ajuste lineal sobre todos esos pares de puntos ordenados para demostrar visualmente la enorme dispersión que se tiene entre estas 2 variables:

Modelo y ajuste de datos


Apoyo bibliográfico y fuente de imágenes
Nuestras ideas y conocimientos que podamos tener sobre el tema tratado en esta publicación pueden ampliarse si consultas las referencias:
- Imagen de geralt: Portada para "dispersión de datos"
- Blog: Ajuste de datos mediante curvas
- Guía: Mínimos cuadrados
- Nota: Gráfico de dispersión en R
- Nota: Diagrama de dispersión
las variables de una igualdad,
así que invariablemente encontraremos alguna solución