
SteemSQL is a public MS-SQL database with all the blockchain data.
Yesterday, I announced a maintenance of my servers infrastructure.
More and more people are using SteemSQL and rely on its availability and performance to provide services and information to all Steemit users.
A never-ending growing database
One of the problem we face is that the amount of data managed by the server grows every day.
To give you an idea, here is a graph that shows the daily amount of data added to the blockchain:
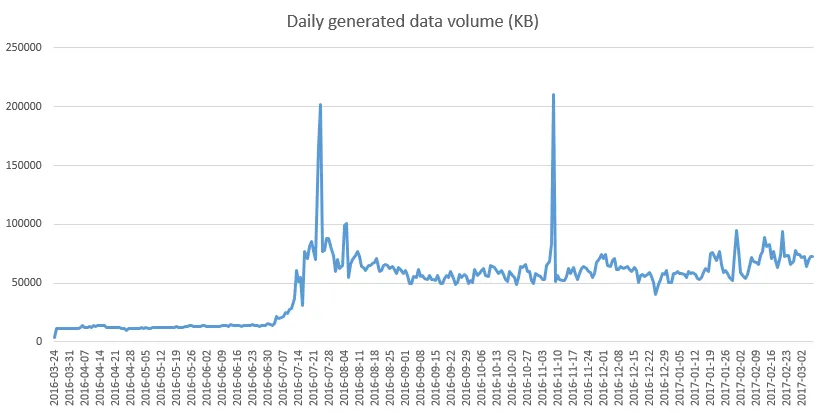
You can see, approximately 80MB of data are added each days to the blockchain. And I consider the Steem blockchain/project as being very young. As more active users are joining Steem, we can expect this amount to increase even faster.
As of writing this post, the database (and the blockchain) contains 17 501 538 blocks and
151 374 729 transactions. Out of these transactions, they are fro example:
- 18 580 045 posts and comments (and 2 803 955 updates of those posts or comments)
- 93 203 786 upvotes (including flags which are negative votes)
- 35 019 218 custom transactions (like follow, resteem, …)
- 4 274 442 author rewards and 28 995 298 curator rewards
SteemSQL database, with the blockchain data, the full text search catalog and all indexes created to improve performances, is already several hundred gigabytes.
SteemSQL under pressure
Everyday, at all time, SteemSQL is put under pressure by thousands of queries, generated by users, apps and bots that rely on SteemSQL to perform their work.
Once again, I will show you some graphs to illustrate this.
The first one, the most impressive to me, is the number of requests per minute SteemSQL had to manage last month:
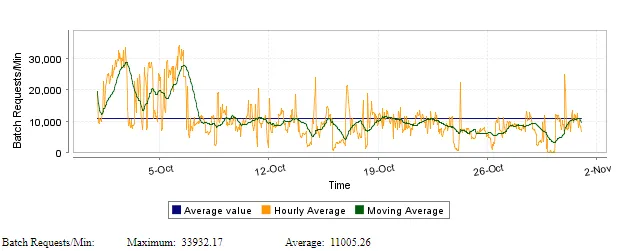
Yes, that's amazing, SteemSQL sometimes deals with up to 33932 queries per minute
Another impressive number is how many locks are made on the different tables. Each time someone is querying data ,or when SteemSQL Database Injector insert new data into the database, it request a lock on the involved table(s).
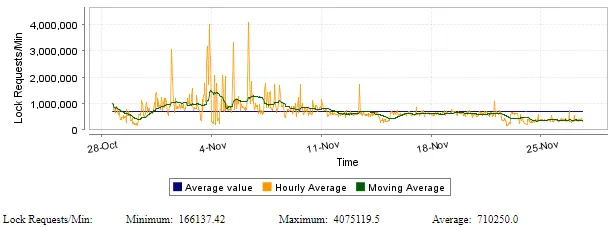
As you can see, at the beginning of this month, SteemSQL had to manage more than 4 millions lock requests per minute. This is why I updated the database design, as explained in this post
Performance matter
When you have to deal with such an amount of data and requests, the main bottleneck are:
The storage performances
The speed of the storage to deliver the data for processing is the key factor. The faster the server can read data, the faster it can use it to make computation.
As user on Voice are more and more active, they server has also to constantly write the new data generated. This can also affect the performances because when you write data, the server put a lock on its database, preventing others to read uncommitted data to avoid computation errors.The computation power
When you have to aggregate several millions of values to compute a sum or an average trend, you need a lot of computation power and preferably, you do not want to be interrupted by others while you are doing the math.The memory
SQL servers put data in cache (in memory) to improve performances. The more memory you have, the more “often used data” the server can keep in its cache, the faster it will process your queries.
A new high-performance dedicated infrastructure
Given the success of SteemSQL and the steady growing load on the server, I have decided to upgrade the underlying infrastructure.
SteemSQL is now hosted on an high-performance fully dedicated infrastructure with brand new processors (4 CPUs running at 3.8Ghz with latest Intel Xeon v6 technology).
The amount of memory has doubled and the storage size, using the latest NVMe technology, has tripled.
On top of this, the server has a guaranteed dedicated 500Mb/s internet bandwidth.
Thanks for reading.
Help SteemSQL stay public and running 24/7/365.
UPVOTE and RESTEEM this post! All payout will be allocated to SteemSQL infrastructure.
Thanks for your support!

Support me and my work as a witness by voting for me here!

Thanks for your support!
Support me and my work as a witness by voting for me here!