
Hello it's a me again Drifter Programming! Today we continue with my simple compiler project. I thought a little bit about the language that we should write the compiler for, and got to the conclusion that C should be just fine. But the problem is that C has some complicated behaviors that will take us months to write and so we will simplify the language to get an easier/simple C.
This means that we will write a compiler for C in C
The good thing is that I did a lot of posts in C and because the tools Flex and Bison also use C we will get even more into C programming now! You can check out my C posts in the recap here. As I already mentioned last time, the Data structures are important and will be needed after we get into Symbol Tables and so check them out if you don't know them yet!
So, let's get started!
The simplified C
To make it easier for me to write an compiler I will use a simplified version of C. This language will look a lot similar to the classic C that we all know and love (yeah maybeeee......)
The changes will be things like:
- less reserved words or keywords (only the basic ones are needed)
- basic data types char, int, float, double, boolean (virtually only to check the conditional statements) arrays (for example a char array for strings), pointers (to all the data types)
- the include statement at the beginning will not be included (funny word-play) and so I will write a simple print function that will be part of the compiler (so that we can get output) and nothing else can be imported
- simple regular expressions for the lexical units or tokens of the Lexical Analysis
- a simplified syntax (that lets us define variables at the beginning only and that doesn't need a main function for example)
- semantic rules that are non-dynamic and so nothing will be checked when the program is running (it's not needed to check things on runtime, cause we are not getting input from somewhere and so the operations are already known)
- Only static memory allocation (for now), which means that the program stack will be used when calling functions, but we will know which variables are needed in that function. This means that the program heap that is used for dynamic memory allocation will be left empty.
By simplifying the language so much we end up with something that is not C anymore. It will look like C, but you will not be able to write any program that you would normally write in C. It's an simple compiler after all anyway!
Comparing with classic C
Let's get into a simple for loop calculation.
Let's say we have a loop counter i and a double variable val.
The variable val will be initialized to 2.5 and we will do 10 iterations and after that print the result (val).
At each iteration we will do:
val = val*i + i.
The C code looks like this:
Note that include needs an hashtag, but we also use it for tags in steemit and so...
include <stdio.h>int main(int argc, char* argv[]){ int i; double val = 2.5; for(i = 0; i < 10; i++){ val = val*i + i; } printf("%f", val);}Simplifying the language we end up with:
int i;double val = 2.5;for(i = 0; i < 10; i++){ val = val*i + i;}print(val);This last language is exactly the language that I will use for my compiler!
You can see that there is no main, that the declarations come first and functions would be under this code that represents the main function. Also note that we use a print() function that will be a part of the compiler...
So, let's now get into the tokens!
Tokens
As you might already know tokens are the lexical units that the program is build up with and can be keywords, operators and even identifiers, constants, strings etc.

Let's get into each category separately.
Keywords:
- CHAR -> to define char datatype
- INT -> to define int datatype
- FLOAT -> to define float datatype
- DOUBLE -> to define double datatype
- IF -> for conditional statement declaration
- ELSE -> else condition
- WHILE -> while loop declaration
- FOR -> for loop declaration
- CONTINUE -> to get to the next iteration of a loop
- BREAK -> to break out of a loop
- VOID -> to declare void datatype or function that doesn't return
- RETURN -> return to function that called (maybe even with return-value) or to the operating system
Operators:
- ADDOP -> + or -
- MULOP -> *
- DIVOP -> /
- INCR -> ++ or --
- OROP -> ||
- NOTOP -> !
- ANDOP -> &&
- EQUOP -> == or !=
- RELOP -> > or < or >= or <=
Identifiers, constants and strings:
- ID's start with a letter and contain character or numbers after that.
- ICONST is a integer constant that can be '0' or anything that starts with a number from 1-9 and is followed by the numbers 0-9 only
- FCONST is a floating point constant that can be '0' or anything that contains zero or more numbers, the character '.' and 1 or more numbers following the dot.
- CCONST is any printable ASCII character in between of two ' or the special character with a '\' in front and in betwen of 2 '. So Line feed is '\n' for example. We will write the regular expression, but because the print function will be custom-made, it will actually be useless.
- STRING's are printable ASCII characters in between of two ".
Other tokens:
- '(' ')' -> parentheses
- '[' ']' -> brackets
- '{' '}' -> bracelets
- ';' '.' ',' -> semi, dot and comma
- '=' '&' -> assign and reference
- (EOF) -> end of file
Comments:
- Anything in a line that starts with '//' is a comment and will be ignored
- Anything in between of '/*' and '*/' that can span through multiple lines is also a comment
Comments aren't actually lexical units, but the Lexer needs to identify them!
So, any program of this simple C will contain only these tokens and anything else will be a lexical error! This also means that the whitespace (spaces, tabs, new lines) will be ignored.
Basic Structure
The syntax and semantic rules will be discussed when we get into Syntax and Semantic Analysis respectively, and we will not get into all of them directly, but add "features" one by one! There is no need to get more in depth now. We will extend the compiler during the series, by changing even stuff that has to do with tokens or syntax rules...
But, to get an idea, here the basic structure of such a program:
main function:
- variable declarations (datatype, name and initialization for variables, arrays and pointers)
- body/statements (arithmetic expressions, if-else, for, while statements, print() and other function calls etc.)
other functions:
- function declaration (return-value datatype, name, parameters)
- variable declarations
- statements
So, an example program might look like this:
// main function// declarationsint i;double val =2.5, res[10];// statementsfor(i = 0; i < 10; i++){ res[i] = operation(val, i); val = res[i]; print(res[i]); print('\n');}return;// functionsdouble operation (double value, int i){ /* function declaration */ // declarations double res; // statements res = value*i + i; return res;}You can see that we have variable i in two different functions!
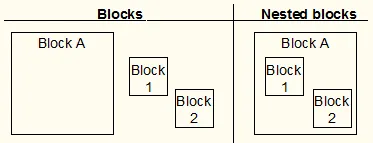
Because of the function we have nested blocks which means that we need a mechanism to check the variable scope! The i of the function will of course be of higher priority then the one of the main function, when we are inside of this function. This is actually not quite difficult to implement and we will talk about such things in Bison. :)
Image Sources:
Previous posts of the series:
Introduction -> What is a compiler, what you have to know and what you will learn.
And this is actually it for today! I hope that you enjoyed it!
Next time we will start getting into the Lexical Analysis of this simplified C language using the C-tool Flex and by writing the regular expressions needed for the Tokens to be recognized of the Lexer!
Bye!