
The Why
Hive engine nodes read all transactions from the HIVE blockchain and when they discover a custom json operation with a special id (ssc-mainnet-hive), they process the transaction and add it to the hive engine sidechain. The hive engine sidechain itself is basically a big database storing all transactions and processed information, such as token balances and nft instances, inside a mongodb.
To create the hive engine sidechain completely from scratch we would have to start from the genesis block and process all transactions after that. This is a very lengthy process, because it includes millions of transactions.
That's where snapshots come into play. You simply create a snapshot of the database after block X was processed and the next time you only have to replay transactions starting from block X. The same principle applies to the HIVE blockchain itself.
So whenever something goes wrong or you want to setup a fresh node you can use the snapshot to set up your node faster.
The What
I am running a hive engine witness node myself, which is why I need to recreate my node regularly. A few other witnesses are already providing snapshots of the hive engine sidechain regularly. I think more is better, so I decided to set up my own daily hive engine snapshots. I have integrated the snapshots into my HIVE monitor tool over here: https://primersion.com/he-snapshots
Every day at 11pm UTC a snapshot is created automatically, uploaded to https://transfer.sh and provided through my page afterwards:
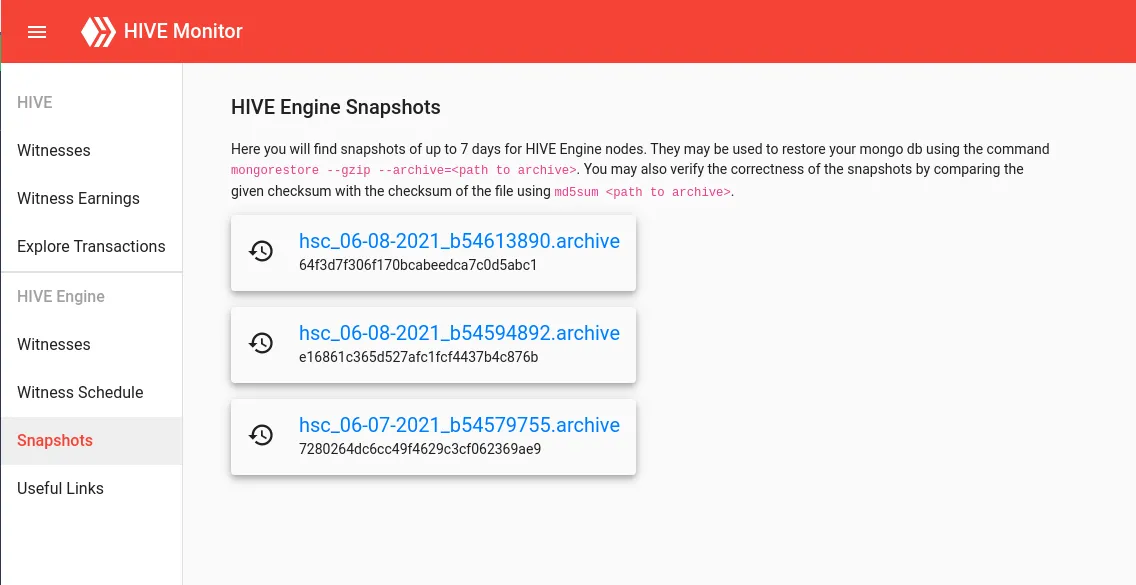
You will find snapshots of the last 7 days (in a few days, because I only started 2 days ago) and you can download them directly by clicking on the link. After downloading the snapshot you can use it to restore the database of your hive engine node using mongorestore --gzip --archive=<path to archive>. Additionally you will find a checksum below the link, which you can compare with the checksum created when running md5sum <path to archive> on the downloaded file.
The How
I have written a small script, which does all the work for me. All I need for it to function is a running and synced hive engine node. First I am stopping my node using pm2 stop all.
In a next step I am dumping the mongodb to a file including the current date and the last processed block:
now=`date +"%m-%d-%Y"`
block=`cat config.json | grep startHiveBlock | grep -Eo '[0-9]*'`
mongodump --db hsc --gzip --archive="hsc_${now}_b${block}.archive"
When the dump is finished I start the node back up using pm2 start app.js --no-treekill --kill-timeout 10000 --no-autorestart.
And transfer the dump to https://transfer.sh using curl --upload-file "hsc_${now}_b${block}.archive" "https://transfer.sh/hsc_${now}_b${block}.archive".
I am running the script daily at 11pm UTC using a cronjob.
That's all the magic.
Please support me by voting for my HIVE / Hive-Engine witness:
HIVE (using Hivesigner)
Hive-Engine (using Votify)