[Image 1]
Introduction
Hey it's a me again @drifter1!Today we continue with the Parallel Programming series about the OpenMP API. I highly suggest you to go read the previous articles of the series, that you can find by the end of this one. The topic of this article is how we specify that SIMD Instructions should be used using OpenMP!
So, without further ado, let's get straight into it!GitHub Repository
Requirements - Prerequisites
- Basic understanding of the Programming Language C, or even C++
- Familiarity with Parallel Computing/Programming in general
- Compiler
- Linux users: GCC (GNU Compiler Collection) installed
- Windows users: MinGW32/64 - To avoid unnessecary problems I suggest using a Linux VM, Cygwin or even a WSL Environment on Windows 10
- MacOS users: Install GCC using brew or use the Clang compiler
- For more Compilers & Tools check out: https://www.openmp.org//resources/openmp-compilers-tools/
- Previous Articles of the Series
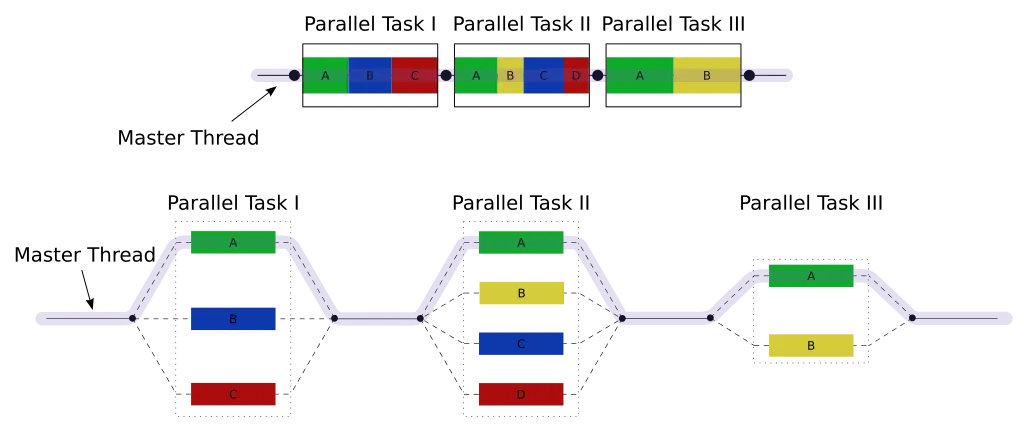
Recap
A parallel region is defined using a parallel region construct:
#pragma omp parallel [clause ...]
{
/* This code runs in parallel */
}int i;
#pragma omp parallel for private(i) [clause ...]
for(i = 0; i < N; i++){
...
}#pragma omp sections [clause ...]
{
/* run in parallel by all threads of the team */
#pragma omp section
{
/* run once by one thread */
}
#pragma omp section
{
/* run once by one thread */
}
...
}#pragma omp single#pragma omp critical [[(name)] [ hint (hint-expr)]] [clause ...]
{
/* critical section code */
}#pragma omp atomic [read | write | update | capture] [hint(hint-expr)] [clause ...]
/* statement expression*/
- omp_init_lock(): Initialize a lock associated with the lock variable
- omp_init_lock_with_hint(): Initialize a lock associated with the lock variable using synchronization hints
- omp_destroy_lock(): Disassociate the given lock variable from any locks
- omp_set_lock(): Acquire the ownership of a lock, and suspend execution until the lock is set
- omp_unset_lock(): Release a lock
- omp_test_lock(): Attempt to set the lock, but don't block if the lock is unavailable
#pragma omp task [clause ...]
{
/* code block */
}Explicit barriers can be placed by using the barrier directive:
#pragma omp barrier#pragma omp flush [(list)]What is SIMD?
Let's start off with the basics. SIMD means Single Instruction on Multiple Data, and can be thought of as Vector Parallelism. In other words, the processors implement special instructions that perform the same calculation on multiple values at once. This is commonly used in GPUs, but can also speed up calculation on CPUs. Most modern CPUs contain AVX instruction extensions in them!
Example
To understand it better let's get into an example.
Let's say we have two one-dimensional vectors of size N, A and B. Our Processing Unit has N different computing units for a specific operation (a vector processing unit for N-sized vectors). An one-dimensional vector of size N, C, is the result of that operation, for each corresponding Ai and Bi.
So, mathematically each element Ci is calculated as follows:
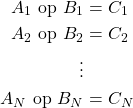
As an SIMD Instruction, this becomes:
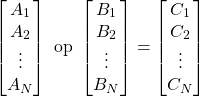
and so all elements, Ci, are calculated in parallel.
If the vector was larger, let's say M, then it would be split into chuncks of size N, so that the operations can be applied in parallel. Each of these vector instructions is padded with No-Op's when no data is available.
SIMD in OpenMP
So, how do we specify that SIMD Instructions should be used to implement a loop?
In order to indicate to the compiler that a for loop should be transformed into SIMD Instructions, we use the - you guessed it - simd directive:
#pragma omp simd [clause]
/* for loops */Clauses
The behavior of the simd directive can be tweaked using the following clauses:
- private, lastprivate - Specify the data-sharing of lists of variables
- reduction - Specify that the compiler should try to reduce the iterations using a specific operator identifier
- collapse - Specify how many nested loops should be associated with the construct
- safelen - Specify the greatest distance between two logical iterations's data (basically when two addresses are independent)
- simdlen - Specify the number of variables to be passed in SIMD registers
- linear - Specify a list of variables that are private and have linear relationship in respect to the iteration space
- aligned - Specify that the list of variables should be aligned to a number of bytes
SIMD in Function Definitions/Declarations
There is also a directive that can be used to specify that a complete function definition (or declaration) should be implemented using SIMD Intructions, so that it can be called from an SIMD loop.
The directive for that purpose is declare simd:
#pragma omp declare simd [clause]
/* function definition or declaration */
This directive can be tweaked using the simdlen, linear and aligned clauses as well as:
- uniform - Specify that the one or more arguments have invariant values for all concurrent invocations of the function
- inbranch - Specify that the function will be called inside of conditional statements of a SIMD loop
- notinbranch - Specify that the function will never be called inside of a conditional statement of a SIMD loop
For Simd Directive
Lastly, OpenMP can also combine the for and simd directive together, using the shortcut:
#pragma omp for simd [clause]
/* for loops */
All clauses that are accepted by simd and for directives can be used to tweak the for simd shortcut.
Example Program
Let's multiply to large vectors element-wise using:
- serial processing
- simd construct
- parallel for construct
- parallel for simd construct
limits.h) each!
[Image 2]
The total ram usage is therefore about 26 Gigabytes!
Don't worry I have 32 gigs - he said...*Behind the scenes*

Well, that was unexpected - he said...Chrome is a ram-eater though, I was already at about 5 Gigabytes without running the code.
To calculate the execution time, we will use the omp function omp_get_wtime(), which gives more accurate results. :)
Vector Allocation and Initialization
The vectors can be defined as pointers to unsigned short and then allocated using calloc:
#define N UINT_MAX
...
unsigned short *A, *B, *C;
/* allocate memory */
A = (unsigned short *) calloc(N, sizeof(unsigned short));
B = (unsigned short *) calloc(N, sizeof(unsigned short));
C = (unsigned short *) calloc(N, sizeof(unsigned short));
...srand(time(NULL));
for(i = 0; i < N; i++){
A[i] = rand() % 256;
B[i] = rand() % 256;
}Serial Processing
The element-wise multiplication of A[i] with B[i] results in C[i] and so can be described by the following for loop:
for (i = 0; i < N; i++){
C[i] = A[i] * B[i];
}SIMD Processing
In order to use simd instructions instead of "generic" instructions, we add an simd directive before the loop:
#pragma omp simd
for (i = 0; i < N; i++){
C[i] = A[i] * B[i];
}Parallel For Processing
This case is also perfect for parallel for loops, and so the loop can be put after a parallel for construct with the loop counter i set as private:
#pragma omp parallel for private(i)
for (i = 0; i < N; i++){
C[i] = A[i] * B[i];
}Parallel For SIMD Processing
Lastly, its also possible to define a parallel for simd construct, which optimizes the loop by executing simd instructions:
#pragma omp parallel for simd private(i)
for (i = 0; i < N; i++){
C[i] = A[i] * B[i];
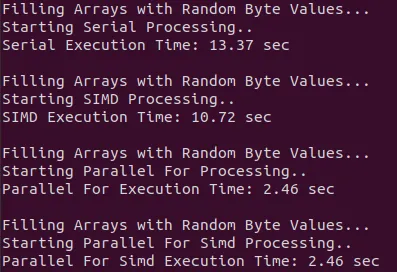
}Console Output
The console outputs:
Conclusion
We conclude that serial processing is by far the slowest. SIMD somewhat speeds up the result, but not by much in the case of this program. And Parallel For or Parallel For SIMD is basically the same, because OpenMP automatically detects that the instructions should be SIMD instructions in this simple case. Either way, combining Parallel For with SIMD Instructions (the parallel for simd construct) is a great way of optimizing our programs, when it can be applied. It might have been some milliseconds in this program, but this could translate into minutes or even hours in complicated algorithms. And also, why should we not use the vector-specific processing units that the CPU offers?
RESOURCES:
References
- https://www.sciencedirect.com/topics/computer-science/single-instruction-multiple-data
- http://ftp.cvut.cz/kernel/people/geoff/cell/ps3-linux-docs/CellProgrammingTutorial/BasicsOfSIMDProgramming.html
- https://www.openmp.org/resources/refguides/
- https://computing.llnl.gov/tutorials/openMP/
- https://bisqwit.iki.fi/story/howto/openmp/
- https://nanxiao.gitbooks.io/openmp-little-book/content/
Images

Previous articles about the OpenMP API
- OpenMP API Introduction → OpenMP API, Abstraction Benefits, Fork-Join Model, General Directive Format, Compilation
- Parallel Regions in OpenMP → Parallel construct, Thread management, Basic Clauses, Example programs
- Parallel For Loops in OpenMP → Parallel For Construct, Iteration Scheduling, Additional Clauses, Example programs
- Parallel Sections in OpenMP → Parallel Sections Construct, Serial Section, Example Program
- Atomic Operations and Critical Sections → Process Synchronization Theory, Critical Section Construct, Atomic Operations, Example Program
- Tasks in OpenMP → Task Construct, Synchronization, Loops and Groups, Example Programs
- Locks and Barriers in OpenMP → Lock and Barrier Synchronization, Flush for Memory Consistency
Final words | Next up
And this is actually it for today's post!I'm not sure what more to cover, so the next article about Parallel Programming might be about Nvidia's CUDA API!
See ya!

Keep on drifting!