[Image 1]
Introduction
Hey it's a me again @drifter1!Today we continue with the Parallel Programming series about the OpenMP API. In the previous articles I gave an Introduction to OpenMP and also covered how we define Parallel Regions. Today we will get into how we define Parallel For Loops.
So, without further ado, let's get straight into it!GitHub Repository
Requirements - Prerequisites
- Basic understanding of the Programming Language C, or even C++
- Familiarity with Parallel Computing/Programming in general
- Compiler
- Linux users: GCC (GNU Compiler Collection) installed
- Windows users: MinGW32/64 - To avoid unnessecary problems I suggest using a Linux VM, Cygwin or even a WSL Environment on Windows 10
- MacOS users: Install GCC using brew or use the Clang compiler
- For more Compilers & Tools check out: https://www.openmp.org//resources/openmp-compilers-tools/
- Previous Articles of the Series
Quick Recap
OpenMP is a parallel programming API thats meant for use in multi-threaded, shared-memory parallelism. Its built up of Compiler directives, Runtime library routines and Environmental variables.
The definition of a compiler directive in the C/C++ implementation of OpenMP is as follows:#pragma omp directive-name [clause ...]gcc -o output-name file-name.c -fopenmp
g++ -o output-name file-name.cpp -fopenmp#pragma omp parallel
{
/* This code runs in parallel */
}- Conditional parallelism - if(condition) clause
- Number of threads - num_threads(int) clause
- Default data sharing - default(...) clause
- List of private variables - private(...) clause
- List of shared variables - shared(...) clause
- Define number of threads - void omp_set_num_threads(int)
- Retrieve number of threads - int omp_get_num_threads()
- Retrieve thread number - int omp_get_thread_num()
- Retrieve maximum number of threads- int omp_get_max_threads()
Parallel For Loop Construct
In the previous article we learned how to define parallel regions. While inside of such a region we can add additional directives like a for loop construct to turn a normal for loop into a parallel for. Of course not all loops can be parallelized that easily and data dependency along the various iterations is quite important to take care of. Furthermore, never forget that the portion of the iterations that each thread of the current team handles may cause the iterations to be executed in an arbitrary order.
For Construct
Using the for loop construct while inside of a parallel region, we basically specify that the iterations of the associated loop (or loops) will be executed in parallel by the threads in the team that has already been created.
The defition of a for loop can be as simple as:
#pragma omp for
for(...){
...
}Parallel For Construct
To define a parallel for loop directly we can use the following syntax:
#pragma omp parallel for
for(...){
...
}
Let's also note that even though the newest C versions allow the loop variable (mostly int i) to be declared inside the loop body, because we have to explicitly set the loop variable as private, we can't use that syntax with OpenMP.
Therefore, a parallel for loop has to be declared in the following generic way:
int i;
#pragma omp parallel for private(i)
for(i = 0; i < N; i++){
...
}Configuration
Of course, as with the parallel construct, OpenMP allows us to configure the for loop to our needs using:
- the default, private and shared clauses (covered last time) - used to define the data sharing (or scoping) of the variables used
- firstprivate clause - define private variables with initial value equal to the shared variables values
- lastprivate clause - define private variabless with last iteration values assigned back to the shared variables
- shedule clause - define how the iterations of the loop should be divided among the threads of the team (more on that later)
- nowait clause - specify if threads should be synchronized (by a barrier) at the end of the parallel loop
- ordered clause - specify if the iterations of the loop should be executed as they would in a serial program
- collapse clause - specify how many loops in a nested loop should be collapsed into one large iteration space
- reduction clause - specify if the compiler should accumulate values from different loop iterations together to reduce the number of iterations
Iteration Scheduling
Let's start of with scheduling.
With the schedule clause we define how the iterations should be divided among the threads.
The format of a schedule clause is:
schedule(kind [, chunk])- kind is the type of scheduling to use
- chunk is the chunk size to use
The kind (or type) of scheduling can be defined as:
- static - Iterations are divided into pieces of size chunk and assigned to the threads of the team in round-robin fashion. When the chunk size is not defined the iterations are (when possible) evenly distributed among the threads.
- dynamic - Each thread executes a chunk of iterations and then requests the next one until none remain. Default chunk size is 1.
- guided - Similar to dynamic, but the chunk size is different for each "assignment" and decreasing until no chunk remains.
- runtime - Scheduling is defined by the environment variable OMP_SCHEDULE at runtime. Specifying the chunk size is illegal.
- auto - Scheduling decision is delegated to the compiler and/or runtime system.
Example Programs
To understand how parallel for loop definitions work, and how we can use some of the clauses to configure them, let's get into some examples...
Basic Parallel For Loop
To learn to fly you first have to learn how to walk, and how to make a simple parallel for loop - very important step(!). So, let's first make a simple for loop that calculates the dot product of two matrices.
Let's:
- declare three matrices: A, B and C with a size of M × N, N × P and M × P respectively (M, N and P are defined by
#definedirectives) - initialize A and B with random values in the range (0, 100] and C with zeros
- make the parallelization conditional using a if clause
- parallelize only the outer-most loop
- calculate the serial and parallel calculation time
The Code for that is:
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define PARALLELISM_ENABLED 1
#define M 800
#define N 800
#define P 800
int main(){
/* declare integer arrays */
int A[M][N], B[N][P], C[M][P];
/* loop counters */
int i, j, k;
/* Calculation time */
time_t start_t, end_t;
double total;
/* initialize arrays */
srand(time(NULL));
for(i = 0; i < M; i++){
for(j = 0; j < N; j++){
/* random value in range (0, 100] */
A[i][j] = 1 + rand() % 100;
}
}
for(i = 0; i < N; i++){
for(j = 0; j < P; j++){
/* random value in range (0, 100] */
B[i][j] = 1 + rand() % 100;
}
}
for(i = 0; i < M; i++){
for(j = 0; j < P; j++){
C[i][j] = 0;
}
}
/* calculate dot product with parallel for loop */
start_t = time(NULL);
#pragma omp parallel for private(i, j, k) if(PARALLELISM_ENABLED)
for(i = 0; i < M; i++){
for(j = 0; j < P; j++){
for(k = 0; k < N; k++){
C[i][j] += A[i][k] * B[k][j];
}
}
}
end_t = time(NULL);
/* Calculate and print Calculation time */
total = difftime(end_t, start_t);
printf("Loop execution took: %.2f seconds (parallelism enabled: %d)\n", total, PARALLELISM_ENABLED);
return 0;
}Loop execution took: 3.00 seconds (parallelism_enabled: 0)
Loop execution took: 0.00 seconds (parallelism_enabled: 1)
time(NULL) isn't that accurate, but I had problems getting clock() to work.
Anyway, we conclude that the parallel execution is much faster.
Firstprivate and Lastprivate Clauses
The firstprivate clause specifies that a private variable should be initialized to the value of the shared one (in private the value would be unspecified), whilst the lastprivate clause stores the last iteration's value of the private variable back into the shared one.
Let's declare an integer x and initialize it to 5. Then let's try and modify its value when x is in the private, firstprivate or lastprivate clause's list.The Code for that is:
#include <omp.h>
#include <stdio.h>
int main(){
int i, x;
/* Tweak shared variable */
x = 5;
printf("before parallelism, x: %d\n\n", x);
/* private x */
printf("private(x):\n");
#pragma omp parallel for private(i, x)
for(i = 0; i < 10; i++){
if(i == 0){
printf("thread %d, before tweak, x: %d\n", omp_get_thread_num(), x);
x = 0;
printf("thread %d, after tweak, x: %d\n\n", omp_get_thread_num(), x);
}
}
printf("after private(x), x: %d\n\n", x);
/* first private x */
printf("firstprivate(x):\n");
#pragma omp parallel for private(i) firstprivate(x)
for(i = 0; i < 10; i++){
if(i == 0){
printf("thread %d, before tweak, x: %d\n", omp_get_thread_num(), x);
x = 0;
printf("thread %d, after tweak, x: %d\n\n", omp_get_thread_num(), x);
}
}
printf("after firstprivate(x), x: %d\n\n", x);
/* last private x */
printf("lastprivate(x):\n");
#pragma omp parallel for private(i) lastprivate(x)
for(i = 0; i < 10; i++){
if(i == 9){
printf("thread %d, before tweak, x: %d\n", omp_get_thread_num(), x);
x = 0;
printf("thread %d, after tweak, x: %d\n\n", omp_get_thread_num(), x);
}
}
printf("after lastprivate(x), x: %d\n", x);
return 0;
}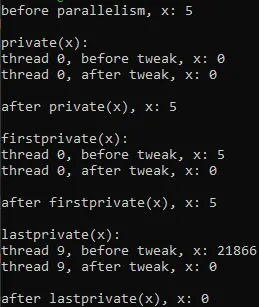
We conclude that:
- private(x) and firstprivate(x) don't affect the shared variable x, whilst lastprivate(x) affects it if it's changed during the last iteration
- private(x) and lastprivate(x) have an unspecified value equal to 0 and 21866 (changes per execution) correspondingly, whilst firstprivate(x) is initialized to 5, which is the value of the shared variable x
Adding Schedule and Collapse Clauses
Using the collapse clause we can define how many of the nested for loops should be parallelized. In the case of the matrix dot product calculation we can use up to collapse(3), but a value of 2 gave far better results. Using the schedule clause we can easily change the iteration scheduling. Let's use guided here. There is not much difference in this simple calculation though.
So, the directive for the for loop changed into:#pragma omp parallel for private(i, j, k) if(PARALLELISM_ENABLED) collapse(2) schedule(guided)The result is also - well - 0.00 seconds again, but feels closer to 0 than 1 second when executing. The previous program more often gave 1.00 in some executions.
Does parallelization always improve the result?
Parallelization doesn't always offer such a dramatic improvement as the one we saw with the matrix dot product.
Sometimes you are better of running an algorithm in serial fashion.
There is a whole theory behind how we should write parallel loops to get the best result, and some algorithms might not be parallelizable at all!
I might get into that later on, in even more advanced examples, but remember that just putting a #pragma omp parallel for might even destroy your algorithm.
There could be data dependencies along the various iterations, and critical sections and the need of synchronization, in order to keep the result the same as the serial algorithm.
Atomic operations and critical sections in general will be covered in a follow-up article!
RESOURCES:
References
- https://www.openmp.org/resources/refguides/
- https://computing.llnl.gov/tutorials/openMP/
- https://bisqwit.iki.fi/story/howto/openmp/
- https://nanxiao.gitbooks.io/openmp-little-book/content/
Images

Previous articles about the OpenMP API
- OpenMP API Introduction → OpenMP API, Abstraction Benefits, Fork-Join Model, General Directive Format, Compilation
- Parallel Regions in OpenMP → Parallel construct, Thread management, Basic Clauses, Example programs
Final words | Next up
And this is actually it for today's post!Next time we will get into Parallel Sections...
See ya!

Keep on drifting!