[Image 1]
Introduction
Hey it's a me again @drifter1!Today we continue with the Parallel Programming series about the OpenMP API. I highly suggest you to go read the previous articles of the series, that you can find by the end of this one. Today we will get into how we define Critical Sections and Atomic Operations.
So, without further ado, let's get straight into it!GitHub Repository
Requirements - Prerequisites
- Basic understanding of the Programming Language C, or even C++
- Familiarity with Parallel Computing/Programming in general
- Compiler
- Linux users: GCC (GNU Compiler Collection) installed
- Windows users: MinGW32/64 - To avoid unnessecary problems I suggest using a Linux VM, Cygwin or even a WSL Environment on Windows 10
- MacOS users: Install GCC using brew or use the Clang compiler
- For more Compilers & Tools check out: https://www.openmp.org//resources/openmp-compilers-tools/
- Previous Articles of the Series
Quick Recap
A parallel region is defined using a parallel region construct:
#pragma omp parallel [clause ...]
{
/* This code runs in parallel */
}int i;
#pragma omp parallel for private(i) [clause ...]
for(i = 0; i < N; i++){
...
}#pragma omp sections [clause ...]
{
/* run in parallel by all threads of the team */
#pragma omp section
{
/* run once by one thread */
}
#pragma omp section
{
/* run once by one thread */
}
...
}#pragma omp parallel sections#pragma omp singleProcess Synchronization Theory
I'm not sure how familiar everyone is with the term Synchronization. Thus, let's first approach the topic from a theoretical perspective.
In general processes can be split into two categories:
- Independent, which are those that don't affect the execution of others
- Cooperative, which are those that affect the execution of others
Independent Processes
If all processes where independent to each other than there would also never be any synchronization problem! As no resources would be shared among the processes.
Cooperative Processes
When multiple processes cooperate they mostly execute the same code, or more specifically access the same resource as others. If no synchronization is applied, in such a case, then the processes would race in order to access the shared resource, making the value of the shared resource uncertain. This is known as the race condition. As several processes access and process the same data concurrently, the output basically depends on the order in which the access takes place.
Critical Section Problem
The race condition that was mentioned previously may occur in a so called critical section. A critical section is a code segment that has to be accessed by only one process at a time. Such sections contain shared variables that need to be synchronized in order to maintain consistency. The critical sections have to be treated as atomic operations and synchronized properly using locks.
In general a critical section can be described as:
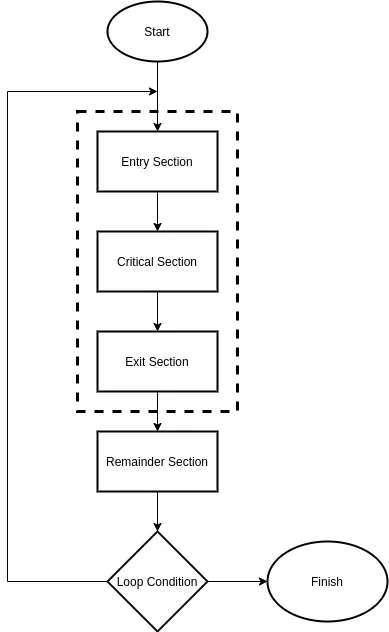
[Custom Figure using draw.io]
- Entry Section: Process requests for entry in the Critical Section
- Critical Section: The code that has to be executed atomically
- Exit Section: Process unlocks the critical seciton for another process to enter
- Remainder Section: The independent code of the process
What OpenMP offers
OpenMP offers lots of ways to synchronize the parallel threads that get created:
- Critical Section Directive: Used to directly specify code that has to be executed by only one thread at a time
- Atomic Operation Directive: Used to directly execute atomic instructions on the CPU
- Runtime Library Lock Routines: Used to define more advanced synchronization using locks
Critical Section Construct
To define a critical section inside of a parallel region in OpenMP the critical section construct has to be used. Using it we specify which specific region of code must be executed by only one thread at a time.
The general format of a critical section construct in C/C++ is:
#pragma omp critical [[(name)] [ hint (hint-expr)]] [clause ...]
{
/* critical section code */
}Critical sections can be given an optional name to enable multiple critical sections to exist. Names act as a global identifier and different critical sections with the same name will be treated as the same section. This means that only one of the critical sections with the same identifier may be executed at any given time, and only by one thread. If all critical sections are unnamed then they are all treated as the same section.
Additionally, its also possible to define something called an synchronization hint. Hints are used for defining the expected dynamic behavior or suggested implementation for locks and atomic or critical directives using the hint clause. The effect of the hint does not change the semantics of the associated construct. There are 5 types of hints that can be used for synchronization, and they can be combined together using the + and | operators:
- omp_sync_hint_none: the default behavior
- omp_sync_hint_uncontented: low contention expected, which means that few threads are expected to perform the operation simultaneously
- omp_sync_hint_contended: high contention expected, which means that many threads are expected to perform the operation simultaneously
- omp_sync_hint_speculative: operation should be implemented using speculative techniques
- omp_sync_hint_nonspeculative: operation should not be implemented using speculative techniques
The same hints with lock instead of sync, in the name, are used for lock synchronization hints.
For example, defining a critical section "update_data" with high contention and speculative implementation is done as follows:
#pragma omp critical(update_data) hint(omp_sync_hint_contended | omp_sync_hint_speculative)
{
/* critical section code */
}Atomic Operations
A critical section construct is the more generic format of data synchronization. If only a specific operation or statement has to be accessed atomically then atomic constructs come into play.
An atomic construct is defined as:
#pragma omp atomic [read | write | update | capture] [hint(hint-expr)] [clause ...]
/* statement expression*/After the word atomic its possible to specify four optional types of atomic expressions:
- read: atomic read expressions, where only reading is guaranteed to happen atomically
- write: atomic write expressions, where only writing is guaranteed to happen atomically
- update: atomic update expressions, where only updating the left-hand-side variable of the statement is guaranteed to happen atomically
- capture: atomic capture expressions, that combine read and update
Atomic Read
#pragma omp atomic read
y = x;Atomic Write
#pragma omp atomic write
y = x;Atomic Update
#pragma omp atomic update
/* Any of the following: */
++x; --x; x++; x--;
x += expr; x -= expr; x *= expr; x /= expr; x &= expr;
x = x+expr; x = x-expr; x = x*expr; x = x/expr; x = x&expr;
x = expr+x; x = expr-x; x = expr*x; x = expr/x; x = expr&x;
x |= expr; x ^= expr; x <<= expr; x >>= expr;
x = x|expr; x = x^expr; x = x<<expr; x = x>>expr;
x = expr|x; x = expr^x; x = expr<<x; x = expr>>x;
In all those statements only updating the value of x is guaranteed to happen atomically.
Atomic Capture
#pragma omp atomic capture
/* Any of the update statements mentioned before */Example Program
Let's fill an enormous byte array with random values which are in the range [0, 255] (all possible 8-bit values). It would be interesting to see how much faster we can count the zeroes in the array in parallel...
Code
Because we want a very large array (I used the maximum unsigned int value or UINT_MAX from limits.h), we have to allocate it dynamically using malloc and of course free it afterwards.
To calculate the total number of zeroes, we have to use an unsigned integer counter that will be updated using an atomic update statement.
Inside of a parallel for loop any thread then accesses the shared array and updates the counter when it finds a zero value.
The execution time can be calculated approximately using the time in seconds since the UNIX epoch.
The code for all that looks like this:
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <time.h>
#define N UINT_MAX
int main(){
unsigned char *A;
unsigned int i, count;
time_t start_t, end_t;
double total;
/* allocate memory */
A = (unsigned char*) malloc(N * sizeof(unsigned char));
/* fill Array with random byte value */
srand(time(NULL));
for(i = 0; i < N; i++){
A[i] = rand() % 256;
}
/* sequential calculation */
count = 0;
start_t = time(NULL);
for (i = 0; i < N; i++){
if(A[i] == 0){
count++;
}
}
end_t = time(NULL);
total = difftime(end_t, start_t);
printf("Sequential Execution Time: %.2f sec, Zeroes in Array: %u or %.2f%%\n",
total, count, (double)count/UINT_MAX * 100);
/* parallel calculation */
count = 0;
start_t = time(NULL);
#pragma omp parallel for private(i)
for (i = 0; i < N; i++){
if(A[i] == 0){
#pragma omp atomic update
count++;
}
}
end_t = time(NULL);
total = difftime(end_t, start_t);
printf("Parallel Execution Time: %.2f sec, Zeroes in Array: %u or %.2f%%\n",
total, count, (double)count/UINT_MAX * 100);
/* free memory */
free(A);
return 0;
}Console Output
Compiling and Executing the program we get the following output:

As you can see, the parallel execution was much faster, because the critical section was only triggered in approximately 0.39% of the parallel distributed iterations of the for loop.
RESOURCES:
References
- https://www.geeksforgeeks.org/introduction-of-process-synchronization/?ref=lbp
- https://www.openmp.org/resources/refguides/
- https://computing.llnl.gov/tutorials/openMP/
- https://bisqwit.iki.fi/story/howto/openmp/
- https://nanxiao.gitbooks.io/openmp-little-book/content/
Images

Previous articles about the OpenMP API
- OpenMP API Introduction → OpenMP API, Abstraction Benefits, Fork-Join Model, General Directive Format, Compilation
- Parallel Regions in OpenMP → Parallel construct, Thread management, Basic Clauses, Example programs
- Parallel For Loops in OpenMP → Parallel For Construct, Iteration Scheduling, Additional Clauses, Example programs
- Parallel Sections in OpenMP → Parallel Sections Construct, Serial Section, Example Program
Final words | Next up
And this is actually it for today's post!Next time we will get into Tasks, which allow us to define more advanced work-sharing...
See ya!

Keep on drifting!