Hallo Leute, Hello Folks (english see below)
In Youtube Videos oder in Newslettern erfahre ich die neuesten Möglichkeiten und Tools im KI Umfeld. Das ist ja immer schön zu sehen, aber manches davon will auch ausprobiert werden.
So bin ich beim LLM-Scraper hängen geblieben.
Dieses kleine Tool liest Webseiten aus und kann sie mit Hilfe von KI auf Kernpunkte zusammenfassen.
Ein Feature, welches ich schon länger mal für Hive anwenden wollte, bisher aber nicht dazu gekommen bin.
Nun habe ich es ausprobiert und möchte euch an meinen Ergebnissen Teil haben lassen:

Erstellt mit Bing
llm Scraper
Das Programm wurde von mishushakov Entwickelt und liegt hier: https://github.com/mishushakov/llm-scraper
Um es laufen zu lassen habe ich folgendes durchgeführt:
Ich habe eine Git-Bash geöffnet und bin in meinen Git-Ordner gewechselt. Dort habe ich git clone ausgeführt:
User@DESKTOP-RVPAUUG MINGW64 ~/git
$ git clone https://github.com/mishushakov/llm-scraper.git
Es mussten noch ein paar Bibliotheken herunter geladen werden:
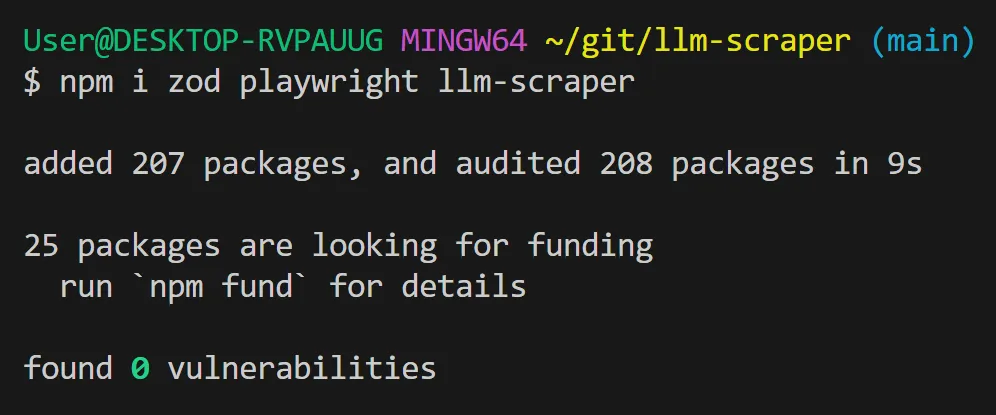
npm i zod playwright llm-scraper
Dann habe ich eine neue Datei "HelloWorld.js" erstellt und die Beispielbefehle aus der README.md dort rein kopiert (fertiges Script siehe unten).
Beim Ausführen gab es eine Fehlermeldung, weil Playwright noch nicht installiert war:
$ node HelloWorld.js
node:internal/process/esm_loader:97
internalBinding('errors').triggerUncaughtException(
Das habe ich nachgeholt mit:
npx playwright install
Jetzt wird bemängelt, dass der OpenAI_API_Key noch fehlt. Das ändern wir wie folgt:
import { OPENAI_API_KEY } from './config.js';
const llm = new OpenAI({ apiKey: OPENAI_API_KEY });
... und erstellen die Datei config.js mit folgendem Inhalt:
// config.js
export const OPENAI_API_KEY = 'sk-uB***********************************ph';
Wichtig: Dieser Dateiname (config.js) muss in der .gitignore hinzugefügt werden, weil sonst beim Hochladen bei Git der Schlüssel entdeckt und sofort bei OpenAI ungültig gemacht wird.
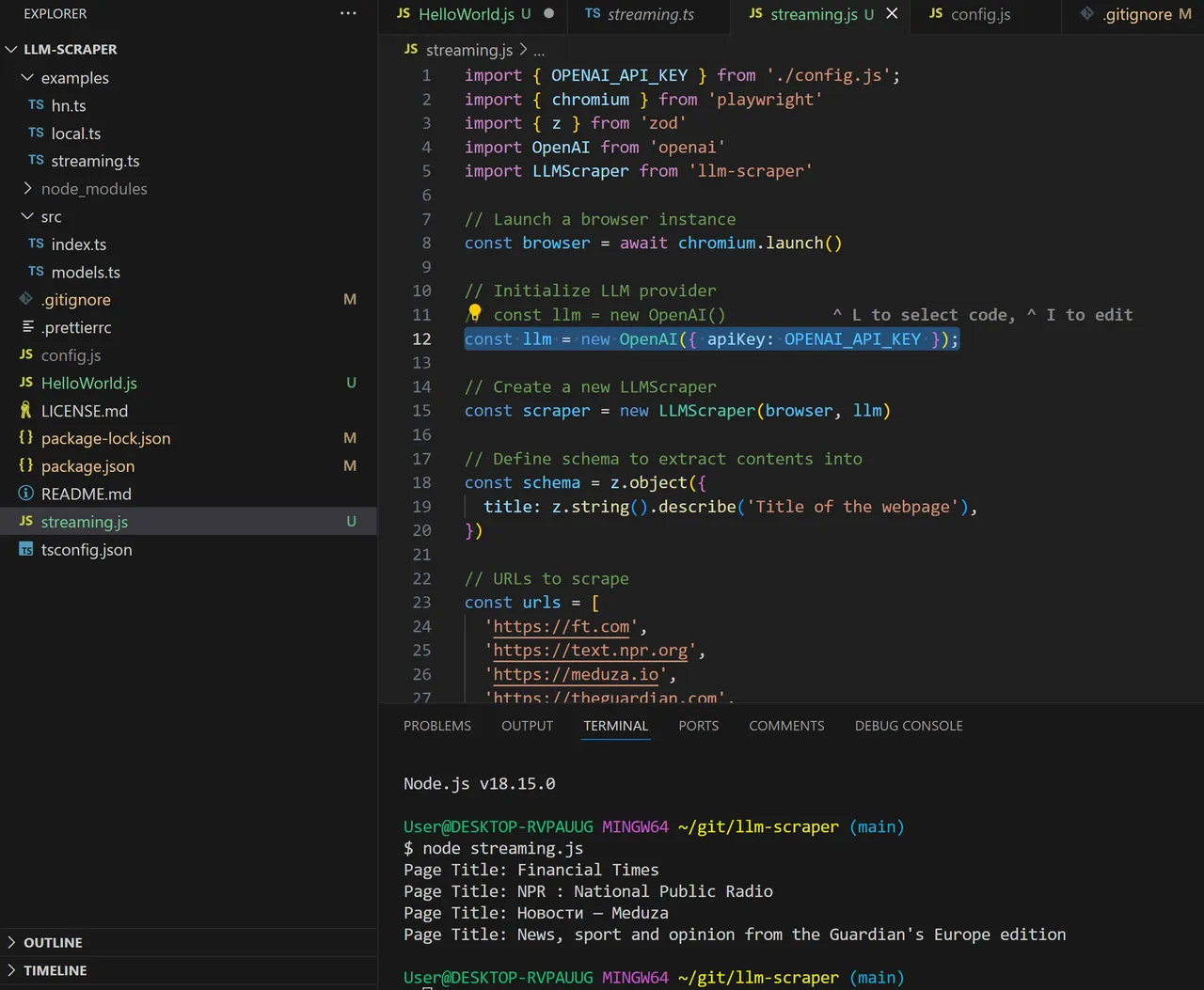
Hier nun der funktionierende Code:
import { OPENAI_API_KEY } from './config.js';
import { chromium } from 'playwright'
import { z } from 'zod'
import OpenAI from 'openai'
import LLMScraper from 'llm-scraper'
// Launch a browser instance
const browser = await chromium.launch()
// Initialize LLM provider
//const llm = new OpenAI()
const llm = new OpenAI({ apiKey: OPENAI_API_KEY });
// Create a new LLMScraper
const scraper = new LLMScraper(browser, llm)
// Define schema to extract contents into
const schema = z.object({
top: z
.array(
z.object({
title: z.string(),
points: z.number(),
by: z.string(),
commentsURL: z.string(),
})
)
.length(5)
.describe('Top 5 stories on Hacker News'),
})
// URLs to scrape
const urls = ['https://news.ycombinator.com']
//const urls = ['https://peakd.com/@achimmertens']
// Run the scraper
const pages = await scraper.run(urls, {
model: 'gpt-4-turbo',
schema,
mode: 'html',
closeOnFinish: true,
})
// Stream the result from LLM
for await (const page of pages) {
console.log(page.data)
}
Es funktioniert
Nun lassen wir das Script laufen. Bei mir hat es geklappt. Ich sehe von der Webseite die Zusammenfassung in form einer JSON-Datenstruktur:
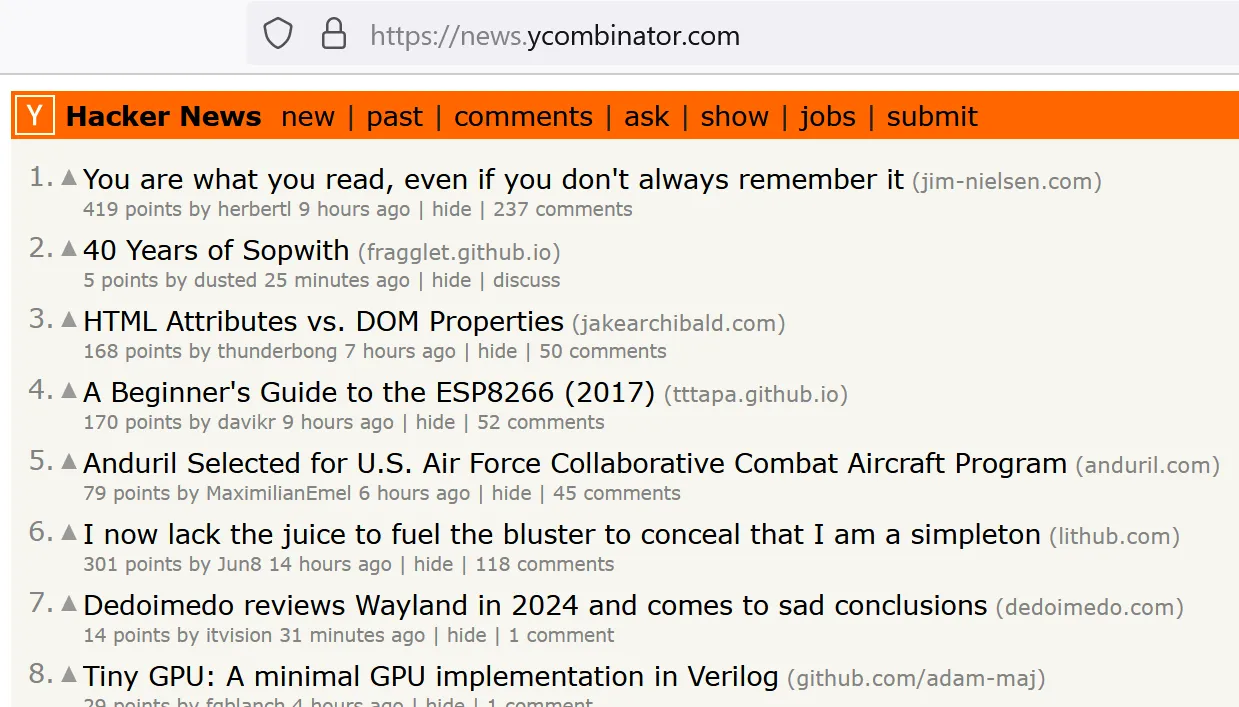
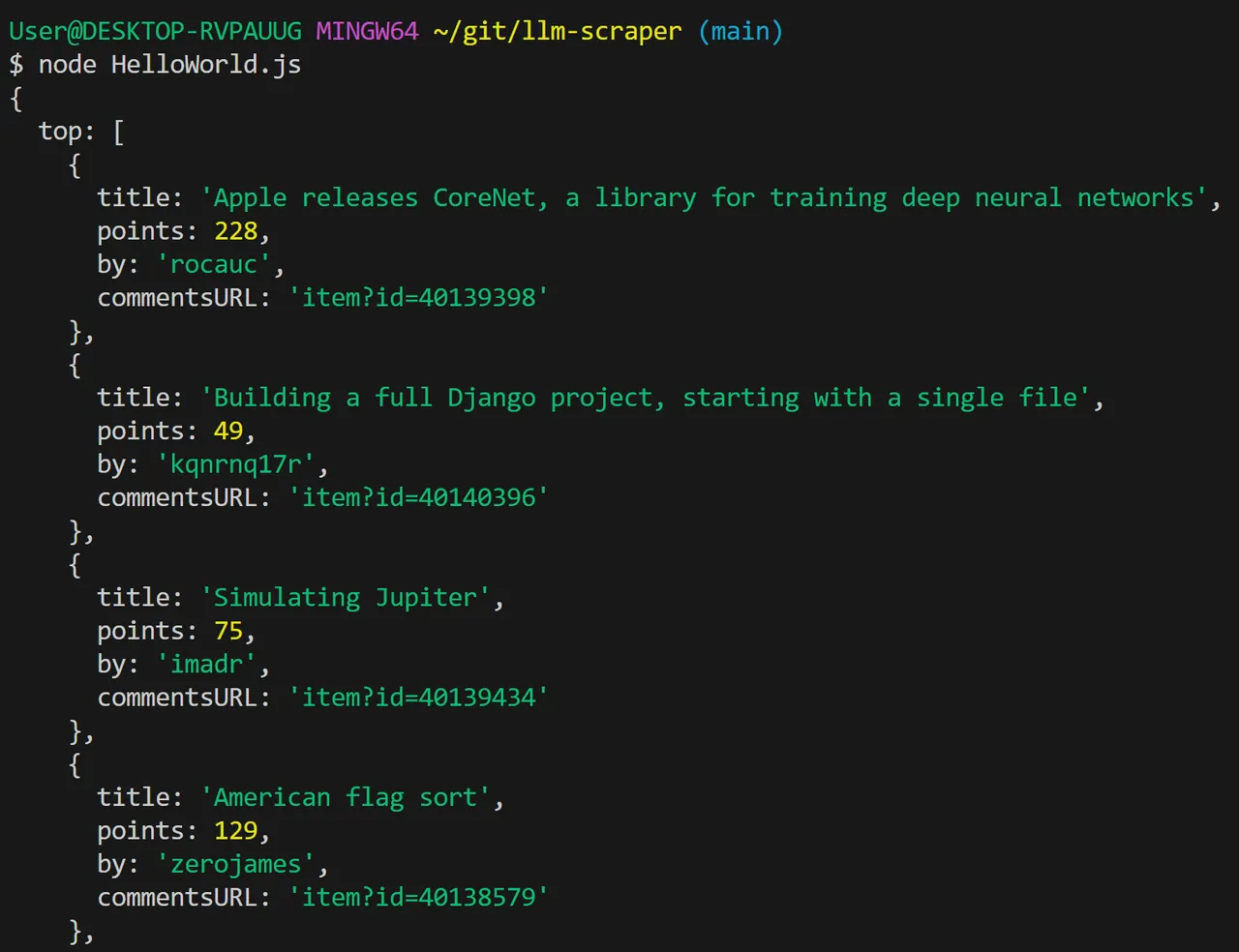
(Die Daten sind unterschiedlich, weil ich die Screenshots zu unterschiedlichen Zeiten gemacht habe)
Weitere Beispiele
Wenn man die anderen Beispiele aus dem 'examples' Ordner nutzen möchte, muss man sie wie folgt umschreiben:
1. Kopieren und einfügen ins Root Verzeichnis
2. Umbenennen nach *.js
3. llmScraper-Location korrigieren: import LLMScraper from 'llm-scraper'
4. Einfügen von:
import { OPENAI_API_KEY } from './config.js';
const llm = new OpenAI({ apiKey: OPENAI_API_KEY });
5. Starten mit (Beispiel): node streaming.js
Was bei mir nicht geklappt hat
Das für mich eigentlich interessanteste Feature war, eine lokale KI laufen zu lassen.
Diese muss zuerst heruntergeladen und gefunden werden. Bei mir liegen die llms aus Platzgründen auf einer anderen Festplatte. Immerhin konnte ich sie wie folgt einbinden:
Im Git Ordner, wo der Code liegt, folgenden symbolischen Link erstellen:
$ ln -s E:/\BENUTZERORDNER/\Mertens/\GPT4All3/\llama-2-7b-chat.Q4_0.gguf llama-2-7b-chat.Q4_0.gguf
Damit kann das Model importiert werden:

Leider läuft das Programm immer wieder aus dem Ruder. D.h. es wird die Webseite aufgerufen und der Inhalt herunter geladen. Dann startet das Model mit der Analyse und dann beendet sich das Programm, ohne auf das Ergebnis zu warten. Ich habe jetzt mehrere Stunden in die Scripte investiert und gebe an dieser Stelle auf (ist ja auch nicht so wichtig).
Wenn jemand von euch ähnliche Scripte geschrieben hat, würde ich mich über Links zu Github freuen, wo ich den Code mit meinem vergleichen kann.
Gruß, Achim
Hello folks,
I find out about the latest possibilities and tools in the AI environment in YouTube videos or newsletters. That's always nice to see, but some of it also needs to be tried out.
So I got stuck with the LLM scraper.
This small tool reads websites and can summarize them into key points using AI.
A feature that I've wanted to use for Hive for a long time, but haven't gotten around to it yet.
Now I've tried it and would like to share my results with you:
Created with Bing
llm scraper
The program was developed by mishushakov and is located here: https://github.com/mishushakov/llm-scraper
To get it running I did the following:
I opened a Git bash and went to my Git folder. There I ran git clone:
User@DESKTOP-RVPAUUG MINGW64 ~/git
$ git clone https://github.com/mishushakov/llm-scraper.git
A few libraries still had to be downloaded:
npm i zod playwright llm-scraper
Then I created a new file “HelloWorld.js” and copied the example commands from the README.md into it (see finished script below).
When I ran it, I got an error message because Playwright wasn't installed yet:
$ node HelloWorld.js
node:internal/process/esm_loader:97
internalBinding('errors').triggerUncaughtException(
I fixed that with:
npx playwright install
Now there is criticism that the OpenAI_API_Key is still missing. We change that as follows:
import { OPENAI_API_KEY } from './config.js';
const llm = new OpenAI({ apiKey: OPENAI_API_KEY });
... and create the file config.js with the following content:
// config.js
export const OPENAI_API_KEY = 'sk-uB************************************ph';
Important: This file name (config.js) must be added in the .gitignore, otherwise the key will be discovered when uploading to Git and immediately invalidated by OpenAI.
Here is the working code:
import { OPENAI_API_KEY } from './config.js';
import { chromium } from 'playwright'
import { z } from 'zod'
import OpenAI from 'openai'
import LLMScraper from 'llm-scraper'
// Launch a browser instance
const browser = await chromium.launch()
// Initialize LLM provider
//const llm = new OpenAI()
const llm = new OpenAI({ apiKey: OPENAI_API_KEY });
// Create a new LLMScraper
const scraper = new LLMScraper(browser, llm)
// Define schema to extract contents into
const schema = z.object({
top: z
.array(
z.object({
title: z.string(),
points: z.number(),
by: z.string(),
commentsURL: z.string(),
})
)
.length(5)
.describe('Top 5 stories on Hacker News'),
})
// URLs to scrape
const urls = ['https://news.ycombinator.com']
//const urls = ['https://peakd.com/@achimmertens']
// Run the scraper
const pages = await scraper.run(urls, {
model: 'gpt-4-turbo',
schema,
mode: 'html',
closeOnFinish: true,
})
// Stream the result from LLM
for await (const page of pages) {
console.log(page.data)
}
It works
Now let's run the script. With me it worked. I see the summary from the website in the form of a JSON data structure:
(The dates are different because I took the screenshots at different times)
Further examples
If you want to use the other examples from the 'examples' folder, you have to rewrite them as follows:
- Copy and paste into the root directory
- Rename to *.js
- Correct llmScraper location: import LLMScraper from 'llm-scraper'
- Inserting:
import { OPENAI_API_KEY } from './config.js';
const llm = new OpenAI({ apiKey: OPENAI_API_KEY }); - Start with (example): node streaming.js
Which didn't work for me
The most interesting feature for me was running a local AI.
This must first be downloaded and found. For me, the llms are on another hard drive for space reasons. At least I was able to integrate them like this:
In the Git folder where the code is located, create the following symbolic link:
$ ln -s E:/\USERFOLDER/\Mertens/\GPT4All3/\llama-2-7b-chat.Q4_0.gguf llama-2-7b-chat.Q4_0.gguf
This allows the model to be imported:
Unfortunately, the program keeps getting out of hand. This means the website is accessed and the content is downloaded. Then the model starts the analysis and then the program exits without waiting for the result. I've now invested several hours in the scripts and I'm giving up at this point (it's not that important).
If any of you have written similar scripts, I would be happy to receive links to Github where I can compare the code with mine.
Greetings, Achim