
Below is a list of Hive-related programming issues worked on by BlockTrades team during last week or so:
Hived work (blockchain node software)
Continued development of TestTools framework
We made a substantial number of changes to the new TestTools framework that we are now using to do blackbox testing on hived: https://gitlab.syncad.com/hive/hive/-/merge_requests/278
There are too many changes to discuss individually (see the merge request for full details), but at a high-level, the new testing framework allows us to perform more complex tests faster and more efficiently than the previous framework.
Command-line interface (CLI) wallet enhancements
We continued work on improvements to CLI wallet (refactoring to remove need for duplicate code to support legacy operations, upgrading cli wallet tests to use TestTools, support for signing of transactions based on authority) and I expect we’ll merge in these changes in the coming week.
Continuing work on blockhain converter tool
We’re also continuing work on the blockchain converter that generates a testnet blockchain configuration form an existing blocklog. Most recently, we added multithreading support to speed it up and those changes are being tested now. You can follow the work on this task here: https://gitlab.syncad.com/hive/hive/-/commits/tm-blockchain-converter/
Hivemind (2nd layer applications + social media middleware)
Reduced peak memory consumption
We reviewed and merged in the changes to reduce memory usage of hive sync (just over 4GB footprint now, whereas previous peak usage was approaching 14GB). Finalized changes that were merged in are here: https://gitlab.syncad.com/hive/hivemind/-/merge_requests/527/diffs
Optimized update_post_rshares
We completed and merged in the code that I mentioned last week that creates a temporary index for faster execution of the update_post_rshares function and we were finally able to achieve the same speedup in a full sync of hivemind on one of our production systems after some tweaks to the code (function with temporary index processed 52 million blocks in 19 minutes).
To achieve the same results that we saw in our development testing, we found we had to perform a vacuum analyze on the hive_votes table prior to running the update_post_rshares function to ensure the query planner had the proper statistics to generate an efficient query plan. The merge request for the optimized code is here:
https://gitlab.syncad.com/hive/hivemind/-/merge_requests/521
Optimized process of effective_comment_vote operation during massive sync
When we know that a particular post will be paid out before end of massive sync block processing, we can skip processing of effective_comment_vote_operations for such posts. This optimization reduced the amount of post records that we need to flush to the database during massive sync by more than 50%. The merge request for this optimization is here: https://gitlab.syncad.com/hive/hivemind/-/merge_requests/525
Merged in new hive sync option --max-retries
We also finished review and testing of the new –max-retries option that allows configuring how many retries (or an indefinite number of retries) before the hive sync process will shutdown if it loses contact with the hived serving blockchain data to it: https://gitlab.syncad.com/hive/hivemind/-/merge_requests/526
Optimized api.hive.blog servers (BlockTrades-supported API node)
While there are number of API nodes available nowadays, many Hive apps default to using our node (which is often useful, since it allows us to quickly spot any scaling issue that might be arising as Hive API traffic increases with time). Here is a graph of how that traffic has increased over the last year:
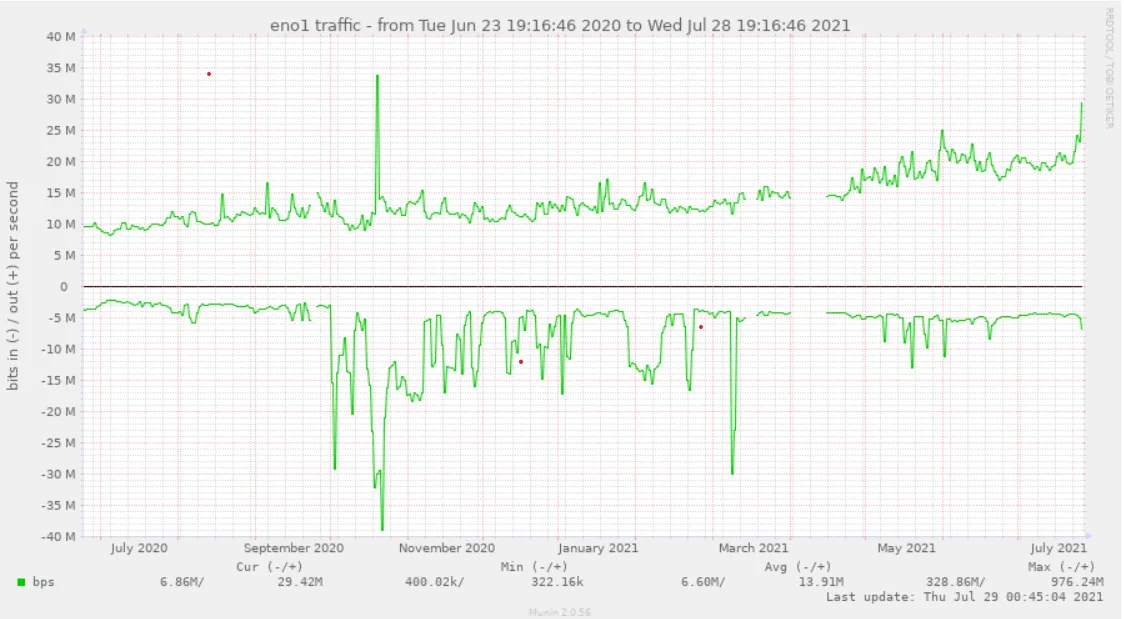
As you can see, our incoming API traffic (the top part of the graph) has roughly tripled over the year.
Solved issue with transaction timeouts
Yesterday we started getting some reports of timeouts on transactions processed via api.hive.blog. The immediate suspicion, of course, was that this was due to the increased traffic coming from splinterlands servers, which turned out to be the case.
But we weren’t seeing much CPU or IO loading on our servers, despite the increased traffic (in fact, we had substantial headroom there and we could likely easily handle 12x or more than the traffic we were receiving based on CPU bottlenecking just with our existing servers), so this lead us to suspect a network-related problem.
As a quick fix, we tried making some changes to the network configuration parameters of our servers based on recommendations from @mahdiyari, and we had a report from him that this helped some, but we were still getting reports of a fair number of timeouts, so we decided to do a more thorough analysis of the issue.
To properly analyze the network traffic, we first had to make some improvements to the jussi traffic analyzer that we use to analyze loading, because most of the increased traffic was encoding the nature of the request in the post bodies, which means the details of the request weren’t seen by the analyzer tool (e.g. we couldn’t see exactly what types of requests were creating the network problems). With these changes, the jussi analyzer can now distinguish what type of request is being made, allowing us to see which type of requests were slow and/or timing out.
After making this change, we found that the requests that were timing out were mostly transaction broadcasts using the old style “pre-appbase” format. Requests of this type can’t be directly processed by a hived node, but we run a jussi gateway on api.hive.blog that converts these legacy-formatted requests into appbase-formatted requests (effectively making our node backwards-compatible with these old style requests).
So this was our first clue as to what the real problem was. After investigating how our jussi gateway was configured, we found that the converted requests were being sent to our hived nodes using the websocket protocol, unlike most other requests, which were sent via http. So, on a hunch, we modified the configuration of our jussi process to send translated requests as http requests instead of web socket requests and this eliminated the timeouts (as confirmed by both the jussi analyzer, beacon.peakd.com, and individual script testing by devs).
At this point, our node is operating very smoothly, despite signs that traffic has further increased beyond even yesterday’s traffic, so I’m confident we’ve solved all immediate issues.
Replacement of calls to broadcast_transaction_synchronous with broadcast_transaction
Despite handling traffic fine now, I’m also a bit concerned about the use of broadcast_transaction_synchronous calls. These are blocking calls that tend to hold a connection open for 1.5s or more on average (half a block interval) because they wait for the transaction be included in the blockchain before returning.
I’ve asked the library devs to look into changing their libraries to begin relying on the newer broadcast_transaction operation (a non-blocking call) and use the transaction_status API call to determine when their transaction has been included into the block, which should eliminate the large number of open connections that can occur when many transactions are being broadcast at once.
@mahdiyari has already made changes to hive-js (the Javascript library for hive apps) along these lines (as well as replacing the use of legacy-formatted API calls with appbase formatted API calls) and apps developers are now beginning to test their apps with this beta version of hive-js. Assuming this process goes smoothly, I anticipate that other library devs will swiftly follow suit.
Hive Application Framework (HAF)
Some enhancements to HAF have been made to support synchronizing of multiple Hive apps operating on a HAF server. This allows an app that relies on the data of other apps to be sure that those apps have processed all blocks up to the point where the dependent app is currently working at. This enhancement also involved support for secure sharing of data between HAF apps on a HAF server (for example, a dependent app can read, but not write, data in the tables of the app it depends on).
As I understand it, we now have a sample application built using HAF, but I haven’t had a chance to review it yet, as I was busy yesterday analyzing and optimizing our web infrastructure with our infrastructure team as discussed above. But this is high on my personal priority list, so I plan to review the work done here soon.
What’s next?
We’ve resumed work on the sql_serializer plugin, which is one of the last key pieces needed before we can release HAF. Once those changes are completed, we’ll be able to do an end-to-end test with hived→sql_serializer→hivemind with a full sync of the blockchain. Perhaps I’m optimistic about the resulting speedup, but it’s possible we could have results as early as next Monday. I’m hoping we have some form of HAF ready for early beta testers within a week or two, but bear in mind that is a best case scenario.