
Dies ist eine Übersetzung des Original-Artikel geschrieben von @blocktrades zur Arbeit an der Hive Software: @blocktrades/19th-update-of-2021-on-blocktrades-work-on-hive-software (Veröffentlicht: Freitag 20 Juli 2021)
Hived Work (Blockchain Node Software)
Cli-wallet Signierungsverbesserung und Fehlerbehebung
Wir haben die Kommandozeilenschnittstelle Wallet erweitert, damit sie Transaktionen mit Kontovollmacht signieren kann. Wir testen dies derzeit.
Wir haben eine Fehlermeldung in der Cli-Wallet behoben
list_my_accounts: https://gitlab.syncad.com/hive/hive/-/issues/173
Leistungsmesswerte für kontinuierliches Integrationssystem
Wir fügen auch Leistungsmetriken für unser automatisiertes Build-and-Test (CI)-System hinzu: https://gitlab.syncad.com/hive/tests_api/-/tree/request-execution-time
Diese Änderungen werden auch für hivemind-Tests vorgenommen:
https://gitlab.syncad.com/hive/tests_api/-/tree/request-execution-time
Diese Arbeit ist noch im Progress.
Letzte Probleme im Zusammenhang mit der Kontohistorie und dem letzten irreversiblen Block behoben
Wir haben außerdem einige Korrekturen im Zusammenhang mit dem Kontoverlauf und dem letzten irreversiblen Block abgeschlossen und einige neue Tests hinzugefügt:
https://gitlab.syncad.com/hive/hive/-/merge_requests/275
Fortsetzung der Arbeit am Blockhain-Konverter-Tool
Wir arbeiten auch weiter an dem Blockchain-Konverter, der eine Testnet-Blockchain-Konfiguration aus einem bestehenden Blocklog erzeugt. Kürzlich haben wir Multithreading-Unterstützung hinzugefügt, um das Tool zu beschleunigen. Die Arbeit an dieser Aufgabe kann hier verfolgt werden: https://gitlab.syncad.com/hive/hive/-/commits/tm-blockchain-converter/
Hivemind (Middleware für 2nd Layer Anwendungen und sozialen Medien)Drastisch reduzierter Speicherverbrauch
Wir haben einige Fortschritte bei dem Problem mit dem Speicherverbrauch von hivemind gemacht. Während es scheint, dass das Leck-Problem verschwunden ist (wahrscheinlich wurde es behoben, als wir die Versionen der Bibliotheksabhängigkeiten, die von hivemind verwendet werden, angepinnt haben), sahen wir immer noch eine höhere als die wünschenswerte Speichernutzung während der Massensynchronisation. Wir haben einige Änderungen vorgenommen (Warteschlangen, die von Consumer/Provider verwendet wurden, waren zu lang, wir haben vorbereitete Abfragen verwendet, wo es möglich war, und wir haben einige Python-Container explizit gelöscht), um diese Zahl zu reduzieren, und wir konnten den Spitzen-Speicherverbrauch von hivemind von über 13 GB auf knapp über 4 GB reduzieren. Die Änderungen sind hier:
https://gitlab.syncad.com/hive/hivemind/-/commits/mt-memory-leak/
Hier ist ein Diagramm der Speichernutzung vor und nach den oben genannten Änderungen:
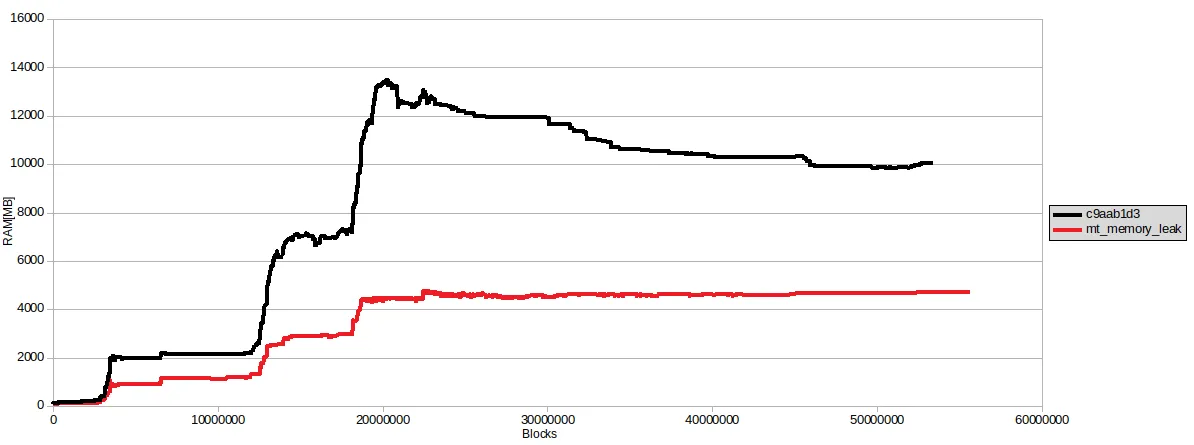
Optimierung von update_post_rshares von 11,4 Std. auf ~15 min.
Wir arbeiten auch weiter an der Optimierung der update_post_rshares-Funktion, die nach der Massensynchronisation ausgeführt wird. Ursprünglich benötigte diese Funktion 11,4 Stunden und wir haben sie durch Hinzufügen eines Indexes auf etwa 15 Minuten reduziert. Ursprünglich war dieser Index ziemlich groß (ca. 25 GB), aber wir haben auch andere Optimierungen vorgenommen, um die Datenbankschreibvorgänge in Bezug auf Beiträge zu reduzieren, die während der Massensynchronisation ausgezahlt werden, und das hat nicht nur die IO-Nutzung reduziert, sondern auch die Größe, die dieser Index benötigt. Es ist auch erwähnenswert, dass dieser Index gelöscht werden kann, nachdem update_post_rshares abgeschlossen ist.
Konfigurierbare Abschaltzeit für Hivemind, wenn es den Kontakt zu hived verliert
Hivemind hatte die lästige Angewohnheit, sich komplett abzuschalten, wenn es den Kontakt zu dem Hived-Nodes verlor, den es zum Abrufen von Blockchain-Daten verwendete (es versuchte es 25 Mal erneut und schaltete sich dann ab). Dies war problematisch, weil dies bedeutete, dass temporäre Netzwerkunterbrechungen hivemind im Stich lassen konnten. Wir haben eine neue Option hinzugefügt, --max-retries (oder -max-allowed-retries, wird noch festgelegt), die standardmäßig auf einen Wert von -1 (unendlich viele Wiederholungen) gesetzt wird.
Außerdem verschieben wir die hivemind Tests aus dem tests-api Repo in das hivemind Repo als Teil einer allgemeinen Umstrukturierung des Testsystems.
Hive Application Framework (HAF)
Unser Hauptentwickler für den forkresolver-Code im HAF ist seit gestern zurück und hat die Arbeit an diesem Projekt wieder aufgenommen. Unser nächster Schritt ist es, mit der Entwicklung einiger Beispielanwendungen für HAF zu beginnen. Ich hoffe, HAF in etwa einem Monat offiziell freigeben zu können. Sobald wir das HAF als Grundlage haben, können wir mit dem Aufbau unseres 2nd-Layer-Smart-Contract-Systems darauf beginnen.
Was steht als nächstes an?
Für den Rest dieser Woche werden wir uns auf die Tests im Zusammenhang mit den oben genannten Aufgaben konzentrieren. In der darauffolgenden Woche werden wir mit der Planung beginnen, welche Aufgaben für den Hardfork 26 vorgesehen sind, sowie andere Aufgaben, die wir planen und die früher freigegeben werden können (da sie keine Protokolländerungen erfordern). Zu solchen Nicht-Hardfork-Aufgaben gehört die Entwicklung von HAF-Anwendungen für den allgemeinen Gebrauch (z.B. eine HAF-Anwendung zur Erzeugung von Tabellen über Hive-Konten und custom_json).